[Originally posted on Turbonomic.com. Posted by Jacob Ben-David.]
During and before re:Invent 2019, Amazon unveiled over 77 new product announcements and unique capabilities. AWS Compute Optimizer, one of the more interesting offerings was quietly announced through a blog on December 3rd.

AWS Compute Optimizer is a new addition to AWS' expanding set of native tools that are focused on helping customers regain control of their cloud bills. The other native tools include AWS Trusted Advisor and Amazon EC2 Resources Optimization Recommendations service (under Cost Explorer), which was unveiled in July 2019.
In this article, we will deep-dive into AWS Compute Optimizer, its capabilities, and how it compares to the existing offerings from AWS.
AWS Compute Optimizer Overview
Compute Optimizer is a Machine Learning (ML) based tool that analyzes CloudWatch metrics of EC2 instances and Auto Scaling groups and generates recommendations to help users with choosing the optimal instance types for their workloads.
Analyzed Metrics
By default, Compute Optimizer will analyze CPU, Storage IO, and network IO utilization (ingress and egress from all NICs), collected from CloudWatch. Users can enable OS-level memory metrics by installing and configuring the CloudWatch Agent.
If memory is not collected, AWS promises that the tool will try not to reduce the memory capacity assigned to EC2 instances. This is an improvement from the Cost explorer rightsizing recommendations.
Amazon recommends enabling detailed monitoring on CloudWatch, which will increase the data collection increments from 5-minutes to 1-minute (note that detailed monitoring on CloudWatch will result in extra charges).
Observation Period
The recommendations will be based on the last 14 days of data; the sampling period is not configurable. Instances must be running for at least 30 hours (in some cases up to 60 hours) before recommendations will be generated.
Recommendations
The first recommendations will show up for eligible EC2 workloads within 12 hours after opting in and enabling the service on your account – from there, the recommendations will refresh and generate daily. The recommendations will leverage five instance families: M (General Purpose), C (Compute Optimized), R (Memory Optimized), T (General purpose with burstable capabilities), and X (Memory Optimized, ideal for in-memory DBs). Any instance assigned with unsupported instance types, such as Accelerated Computing (P, G, and F) or Storage optimized (D, I, and H), will not see recommendations.
The service will analyze usage of EC2 instances and will categorize instances as one of the following (using AWS' language) and will generate sizing recommendations as needed:
- Under-provisioned: An EC2 instance is considered under-provisioned when at least one specification of your instance such as CPU, memory or network, does not meet the performance requirements of your workload.
- Over-provisioned: An EC2 instance is considered over-provisioned when at least one specification of your instance such as CPU, memory or network, can be sized down while still meeting the performance requirements of your workload, and when no specification is under-provisioned.
- Optimized: An EC2 instance is considered optimized when all specifications of your instance such as CPU, memory and network, meet the performance requirements of your workload, and the instance is not over-provisioned. An optimized EC2 instance runs your workloads with optimal performance and infrastructure cost. For optimized resources, Compute Optimizer might sometimes recommend a new generation instance type.
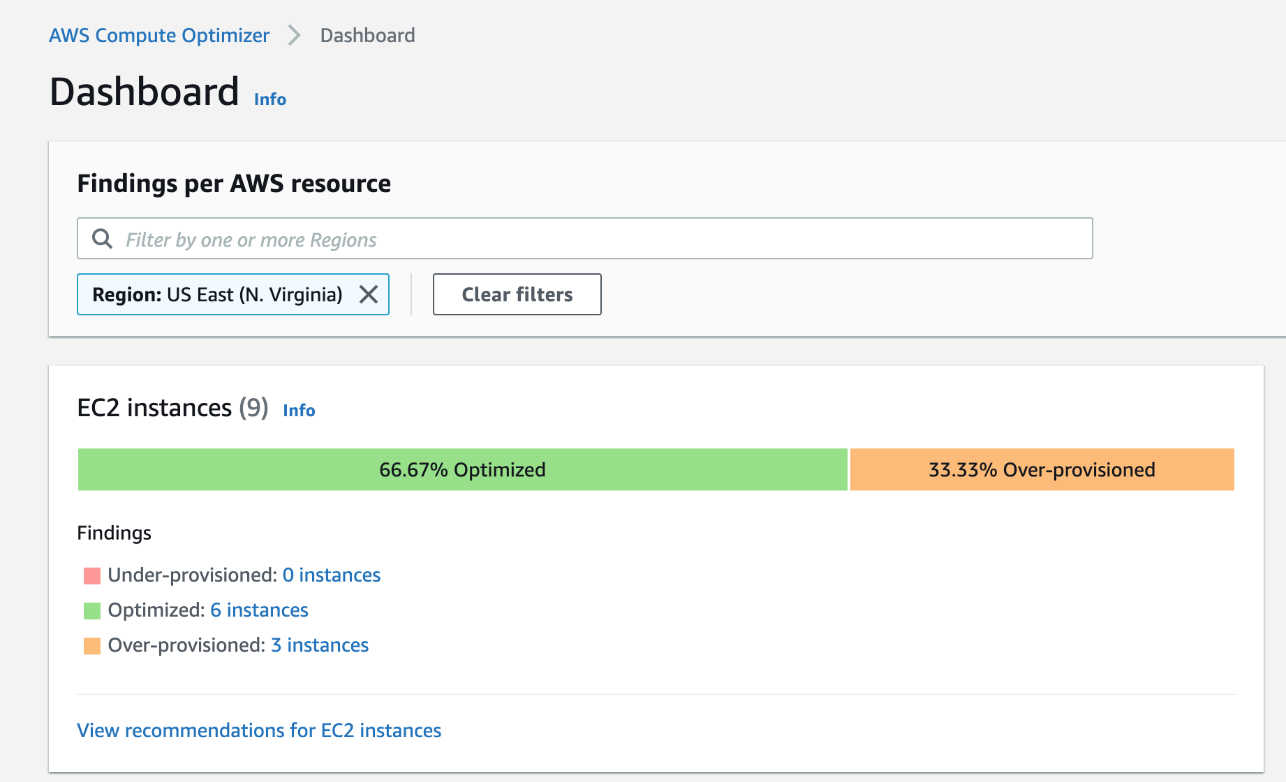
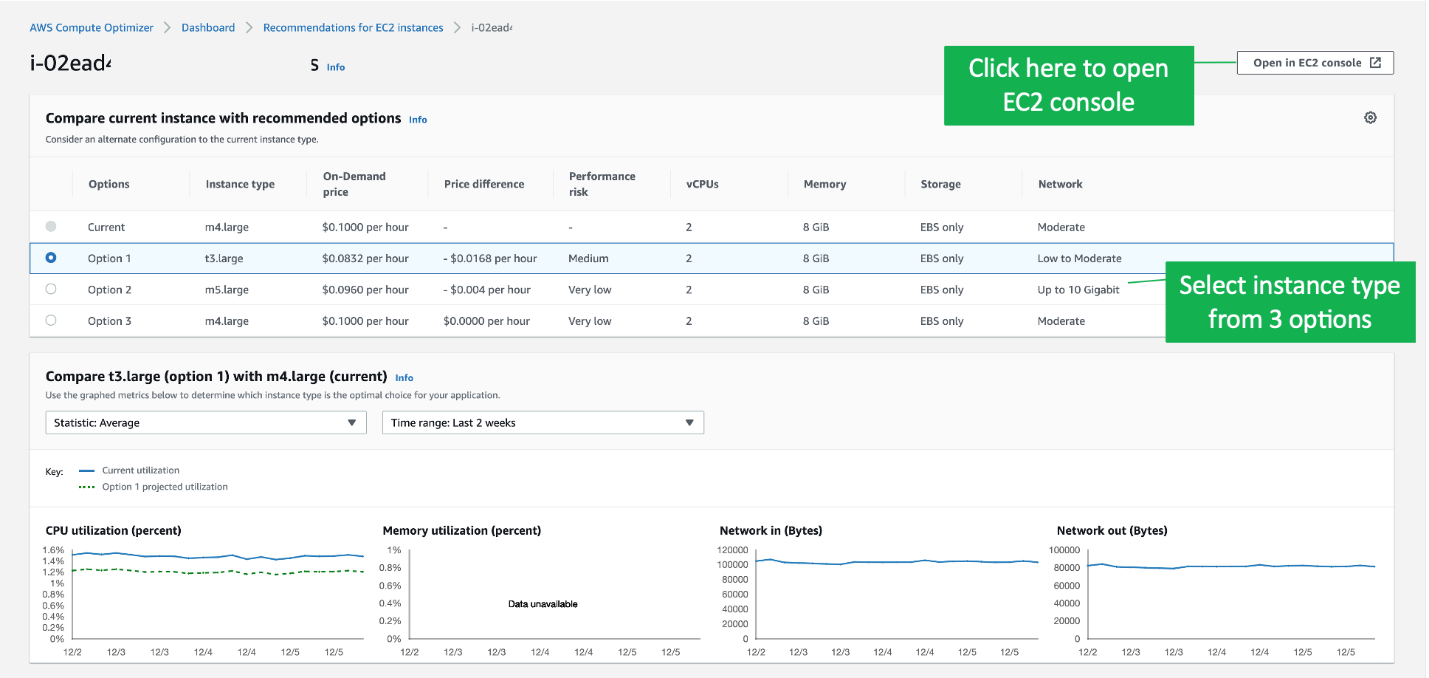
When the tools generate a recommendation for EC2 instances, it will present users with three options to choose from.
Auto Scaling Groups recommendations will focus on optimized and not-optimized auto-scaling groups.
The execution of the recommendation is manual. The tool will provide a direct link to the respected instance page, but users still need to manually stop, select the instance type, and start the instance again.
Analytics Engine
From what we know so far, the rightsizing analytics engine powering this new tool is based on Machine Learning. It analyzes the EC2 workloads' utilization across the supported metrics and uses insights from millions of workloads running on AWS to make its recommendations on which instance size to use.

Image source: https://aws.amazon.com/compute-optimizer/
Amazon did not provide details on the weight of observed peaks and average utilization in determining what a precisely optimized, under-utilized, or over-utilized workload is, but it is important to note that these may not be configurable.
Lastly, it is not clear if the tool considers existing Reserved Instances or Savings Plans when it generates its recommendations or considers the pending RI or Savings plans purchasing recommendations offered in Cost Explorer. This is important since sizing workloads without assessing the current RI inventory may result in higher on-demand charges, especially when doing cross-family sizing.
AWS Compute Optimizer vs. Existing Offerings from AWS
Compute Optimizer provides additional functionality versus the other tools from AWS, namely AWS Trusted Advisor and Cost Explorer EC2 rightsizing recommendations.
The common elements among all tools are the non-configurable observation period of the last 14 days and the lack of any user-customization with regards to rightsizing analytics.
AWS Trusted Advisor identifies and sends an alert when an instance’s CPU utilization has exceeded a threshold to determine efficiency opportunities or performance risks. For example, if an instance’s CPU utilization was 10% or less and network IO was 5MB or less for four or more days, it will be marked as under-utilized. If CPU utilization was more than 90% for four or more days, it would be marked as over-utilized. These thresholds cannot be modified, and users will have to determine what new instance type to use.
The relatively new EC2 rightsizing recommendation service under Cost Explorer is also a threshold-based tool. Any instance with CPU peak below 1% over the last 14 days will be marked as Idle with a recommendation to terminate it (assuming it is not needed). Instances with CPU peaks between 1% and 40% will have a size down recommendation, but within the same instance family (for example from m4.xlarge to m4.large).
With Compute Optimizer, AWS is now offering cross-family rightsizing recommendations (within the five instance types it supports). Compute Optimizer also expands the recommendations to Auto Scaling groups beyond EC2.
Is Compute Optimizer enough?
Compute Optimizer is designed to help AWS users with selecting the right instance types for their workloads. However, when it comes to the "last-mile" of choosing the optimal instances and executing the rightsizing, the onus is on the user.
Furthermore, rightsizing is only one of several methods of reducing cost on the cloud, and it should never be done in isolation without considering the other available options. Other important considerations include using Reserved Instances (or the new AWS Savings Plans) or stopping instances when not needed, for example.
There is no doubt that cloud and application complexity is increasing, while customers are introducing more and more applications. This presents a challenge far beyond human scale. Leveraging CloudWatch is a great start and collecting OS-level metrics via the CloudWatch agent or 3rd-party tool is even better. However, the most effective approach is to let the application drive resource allocation, which is where Turbonomic Application Resource Management comes in.
Compute Optimizer is a useful tool and it will be good enough for small scale organizations or those who are still “figuring out that thing called Cloud”. History thought us that the adoption of native solutions is around 30% and the majority of organizations will require more advanced optimization functionality due to their scale and business requirements.
Gartner recently released a paper called ‘Comparison for AWS, GCP and Microsoft Azure Native Cost Optimization’ (ID: G00448108) by Brian Adler and Marco Meinardi. Although the paper was released before AWS Compute Optimizer was announced it will provide detailed overview of the available tools and advice for organizations. You should read it to understand the level of depth native solutions provide.
Enter Turbonomic Application Resource Management
Turbonomic empowers customers to achieve their goals with applications running in the cloud, and that is leveraging the inherent agility and elasticity of the cloud. From a cost perspective, customers would like to make sure applications have the precise resources they need to perform when they need them. This cannot be achieved through a collection of monitoring and predictive tools as it requires a systemic approach.
Below are few examples of why organizations should use Turbonomic to optimize their cloud or on-premises estate:
- Top-down, application-aware approach - Turbonomic is designed first and foremost to assure application performance. Turbonomic offers multiple agentless options to connect, ingest and act upon application-level metrics such as Heap utilization, Database memory and application response times. The best way to reduce application costs is to focus on application performance first. When you are allocating the exact resources your application needs when it needs them, you will naturally achieve cost reduction without introducing performance risk. Simple as that!
- You need trustworthy actions you can automate, not recommendations - As stated, when using the native cloud offerings, users still need to decide on which exact instance type to use, confirm it meets any constraints (such as drivers for the NICs (ENA) or storage (NVMe), and considering the impact on storage and network ). Then, users have to execute them during the next maintenance window manually; this is not sustainable or scalable! Turbonomic generates trustworthy actions that can (and should) be scrutinized by users before executing them from the Turbonomic UI and once comfortable, fully automating, or even integrating with tools like ServiceNow for approval workflow and audit trail.
- Different workloads require different optimizations approaches - although the Compute Optimizer uses ML to determine users' workload type and match them with few instance types, users told us they still want to configure the rightsizing engine to match their workloads' type. They also want to control the observation period, the aggressiveness of sizing by using percentiles, the target utilization of resources and to be able to apply these different policies to specific apps, accounts, or any group of resources created based on tags, for example.
- Real-Time response to fluctuating demand - unlike Compute Optimizer, which generates and refreshes recommendations daily, Turbonomic's actions are produced continuously in real-time as demand fluctuates.
- Reserved Instances aware rightsizing - Turbonomic will generate sizing actions while considering users' Reserved Instances inventory. For example, if an instance is using on-demand pricing and there is an available RI, Turbonomic will generate a sizing action to that RI even if the workload itself does not need to be resized. In this example, by taking this specific action by Turbonomic, you will benefit from eliminating on-demand costs and avoiding losses related to unutilized RIs for which you have already pre-paid.
- Hybrid and multicloud system - Turbonomic supports on-premises workloads running on any hypervisor, private cloud, or container platforms such as Pivotal Cloud Foundry or Kubernetes. Turbonomic also supports multicloud management, including AWS and Azure IaaS and PaaS services (including managed Kubernetes and Databases), as well as Google GCP for GKE optimization. As a hybrid solution, Turbonomic can also help to accelerate cloud migrations. Many of our customers were able to reduce the number of tools (and related licenses costs) they use in IT by leveraging Turbonomic to manage their entire hybrid & multicloud estate.
Turbonomic Application Resource Management, which was included in another paper by Gartner ‘Solution Comparison for Public Cloud Third- Party Cost Optimization Tools’ (ID: G00441626) which we are extremely proud of and highly recommend that every Gartner subscriber should read it.
In Summary, in the future, we should expect more native cost optimization solutions offered by cloud providers as customers continue to voice their frustration with increasing cloud bills. However, we should remember that the reasons for the cloud cost overruns are rooted in the fact that many operation teams default to the old (on-premises) habits of overprovisioning resources to assure performance, but the only way to manage the tradeoffs between performance is with Application Resource Management