CONDITIONAL PROBABILITY: For two events A and B with P(B) ≠ 0, the Conditional Probability of A given B is defined as P(A|B) = P(A∩B) / P(B).
BAYES’ THEOREM: From the above definition P(A∩B) = P(A|B) P(B). Then for n exhaustive and mutually exclusive sets A1, A2, …, An,
P(Ai|A) = P(A∩Ai) / P(A) = P(Ai|A) P(A) / ∑ P(A∩Ak) = P(Ai|A) P(A) / ∑ P(Ak|A) P(A)
which is Bayes’ Theorem.
NAÏVE BAYES: Consider t classes C1, C2, …, Ct and n observations x1, x2, …, xn. We need to find the class Ck for which P(Ck|x1, x2, …, xn) is maximum over k. Using the definition of Conditional Probability P(Ck|x1, x2, …, xn) = P(Ck, x1, x2, …, xn)/P(x1,x2,…,xn). Now,
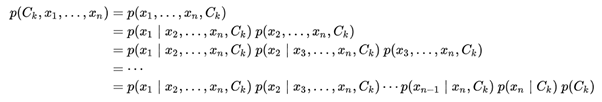
Now the "naïve" conditional independence assumptions come into play: assume that all features in x are mutually independent, conditional on the category Ck. Under this assumption,
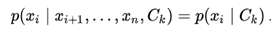
under the above independence assumptions, the conditional distribution over the class variable C is:
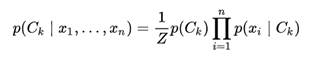
Where Z = P(x) is merely a scaling factor and doesn’t vary over the categories or classes. So the Naïve Bayes algorithm calculates P(Ck|x1, x2, …, xn) for all the classes Ck and chooses the class that has maximum probability.
A BIT OF HISTORY: Naïve Bayes has been studied extensively since the 1960s. It was introduced into the text retrieval community in the early 1960s, and remains a popular baseline method for text categorization, the problem of judging documents as belonging to one category or the other, document categorization such as spam or legitimate, sports or politics, etc., with word frequencies as the features. With appropriate pre-processing, it is competitive in this domain with more advanced methods including support vector machines. It also finds application in automatic medical diagnosis.
In the statistics and computer science literature, naive Bayes models are known under a variety of names, including simple Bayes and independence Bayes. All these names reference the use of Bayes' theorem in the classifier's decision rule, but naïve Bayes is not necessarily a Bayesian method.
SPAM FILTERING: Naive Bayes classifiers work by correlating the use of tokens, typically words, or sometimes other things, with spam and non-spam (ham) e-mails and then using Bayes' theorem to calculate a probability that an email is or is not spam.
Naive Bayes spam filtering is a baseline technique for dealing with spam that can tailor itself to the email needs of individual users and give low false positive spam detection rates that are generally acceptable to users. It is one of the oldest ways of doing spam filtering, with roots in the 1990s.
Variants of the basic technique have been implemented in a number of research works and commercial software products. Many modern mail clients implement Bayesian spam filtering. Users can also install separate email filtering programs. Server-side email filters, such as DSPAM, SpamAssassin, SpamBayes, Bogofilter and ASSP, make use of Bayesian spam filtering techniques, and the functionality is sometimes embedded within mail server software itself. CRM114, oft cited as a Bayesian filter, is not intended to use a Bayes filter in production, but includes the ″unigram″ feature for reference.
NAÏVE BAYES IN PYSPARK: NaiveBayes implements multinomial naive Bayes. It takes an RDD (resilient distributed dataset) of LabeledPoint and an optionally smoothing parameter lambda as input, and output a NaiveBayesModel, which can be used for evaluation and prediction. Note that the Python API does not yet support model save/load but will in the future.
QUESTION I : How justified is the assumption of Conditional Independence in Naïve Bayes?
QUESTION II : Do we need a recurrent procedure in calculating Naïve Bayes probabilities?
#GlobalAIandDataScience#GlobalDataScience