Automating different steps of the Machine Learning Lifecycle
AutoAI (or Automated Data Science) is a profoundly moving field of AI research in academia and the industry. Different public cloud providers develop some form of AutoML capability. Tech unicorns have been expanding AutoML capabilities around their data platforms. Many distinct open-source initiatives are underway, which implement interesting new strategies. Our focus in this blog is not to discuss all of that, but to focus on understanding AutoAI from a data scientist and a business perspective. We will also focus on where and how AutoAI can be used and the current capabilities offered across the ML lifecycle.
AutoAI will not only help data scientists, but will also make non-experts get comfortable with the capability and quickly see the impact. It will improve the efficiency of ML workflows and stimulate AI adoption overall. There is potentially a long-term possibility that AutoML capabilities will make it possible to automate the end-to-end process of employing ML in business use cases.
While keeping those prospects in view, it is equally important to understand the capabilities and limitations of Auto-AI in the near-term?
Here we will explain the concepts, outline current capabilities, and suggest potential improvements needed to automate the whole ML model pipeline completely. I'll discuss the landscape of AutoAI, looking beyond just hyper-parameter optimizing and consider its impact on overall data science activities and complete ML workflow.
What will you learn? 🎓
- AutoAI, AutoML, and what it means
- The different AutoML techniques and current capabilities being used
- Capabilities and shortcomings of AutoML in the near-term, as well as long term possibilities
- How to leverage AutoAI technology to advance the ML end-to-end lifecycle
What is Auto AI?
AutoAI stands for "automation of the AI processes." Precisely, it determines which steps of the ML / DL pipeline that can and should be automated. It centers around automating the ML steps, including but not limited to: data preparation, feature engineering and extraction, model selection, hyper-parameter tuning, optimization, results interpretation, and visual story-telling.
Automating parts of the ML workflow
Although not everything can be automated in the data science workflow, many things can be.
Have a look below at a typical ML workflow, which I presented in my article on Feature Store in April 2020. Feature Store is a part of the big story of AutoAI, and indeed an excellent way to optimize and automate your AI and Data Science workflows. For further details on the feature store, read this blog.
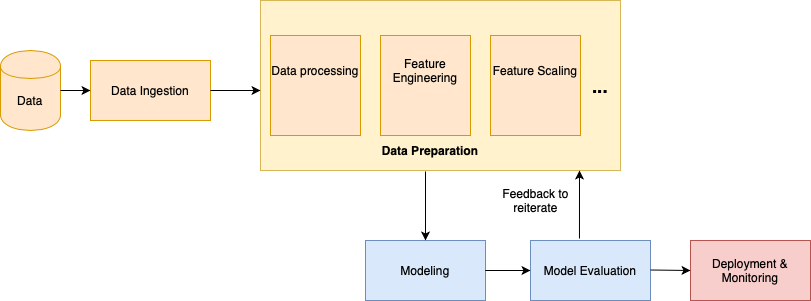
The per-implemented model types and structures can be presented for selection, or can be learned from the input datasets.
AutoAI simplifies the development of AI projects, proof-of-value initiatives, and helps business users speed up ML solutions development without extensive programming knowledge. However, as it stands today, it also serves as a complementary tool for data scientists. It allows data scientists the ability to quickly find out what algorithms to test or see if they have missed some algorithms, with the goal to gain better results.
Business leaders tend to hire data scientists if they have AutoAI tools at their disposal. I would challenge leaders to expand their strategy to consider the bigger picture:
- Data science is like any other business function that must be performed with due diligence and requires creative thinking and human skills to get the best out of it.
- AutoAI is still not there. What we are working with is still Narrow AI, and to which we are nowhere near achieving (General Artificial Intelligence) AGI; once we have that, we could think about living without data scientists, at least for the most parts.
- Data Science is like babysitting; you have to regularly take care of your pipeline, models, data, and other assets.
- Understanding the business and data (the first two steps of the CRISP-DM) model cannot be done by the algorithms; you need a data scientist to do this job, make the data ready to be fed into the ML pipeline.
- Similarly, during the other steps of the pipeline, you still need data scientists and AI experts to ensure that models work correctly and, if anything, needs an adjustment.
- You would also need data scientists to take care of any changes in the business scenarios, data-drift, ML models retraining, and so forth.
- Last but not least, once you get the results and business insights, you would still need the data workers to interpret them and communicate them to the business.
These points are brought up early on here so that you do not confuse the fact that you can proceed with AutoAI and without data scientists. It helps to have both of them in your journey towards AI-based transformation. At the same time, it is important to emphasize the great value that AutoAI offers by shortening the time-to-market for the ML models.There is an increase in the enterprises' tendency to accelerate their AI and ML adoption by automating ML pipelines and different steps in the ML lifecycle. Before we delve into what can be automated, let’s first examine what a standard ML pipeline looks like:
As illustrated in the figure above, the ML pipeline consists of data retrieval, data preparation, modeling, hyper-parameter tuning, model deployment, and monitoring. After the initial data ingestion, we need to remove the duplicates, fix the missing values, and address if there are any potential errors in the data. The next step is to apply feature engineering to extract and engineer the features, followed by obtaining the data for training from the cleaned data-set. This includes encoding the data, feature (re)-scaling, correlation analysis, etc.
Then, we feed these features ready for training to the selected models, followed by hyper-parameter tuning. This selection of models and parameters tuning requires the data scientists to go through this process a few times and compare the models' performance. The resulting models and their results need to be tested and interpreted. In this step, data scientists have to validate the feature importance, detect the potential bias, and interpret the predictions so that the business users could understand the insights and comprehend their relevance for them.
Data Scientists go through this process for every use case, and within each use case, few steps are repeated and time and effort consuming and the costs and delay in getting to production. For this reason, we see AutoAI, or the automation of the ML pipeline, entering scene as a savior, automating many steps of the ML life cycle.
Data Cleaning and Feature Engineering
The first step in an ML pipeline is about data cleaning and feature engineering: Feature + (Selection, Extraction, Construction). AutoAI can help you to detect duplicates, missing values, and other inconsistencies or errors that might exist in the data. After addressing these issues (data cleaning), we transform the attributes in the data to features so that the ML models can consume them. The quality and quantity of the features greatly impact the models and their outcomes.
Feature Selection: The system chooses a subset of features using a search strategy and evaluates them. It does so until it finds such a feature set, which is good for the model.
Feature Construction: Creates new features from the raw data or by combining the existing features.
Feature Extraction: Focuses on dimensionality reduction by using common methods such as PCA, independent component analysis, isomap, etc.
Usually, this step takes a significantly large amount of time from the data scientists, and it is a tedious process. AutoAI solves this problem with increased efficiency and guaranteeing quality features.
Model selection, hyper-parameter tuning and model testing
Two approaches are used in model selection. Traditionally, the data scientists focus on manual model selection: selecting the model from the common ML models (Decision Trees, SVM, Logistic Regression, etc.) based on the data available and suitability of the models. The second approach, which is used by AutoAI, is the Neural Architecture Search (NAS). It tries to design a network architecture using reinforcement learning in the background.
This part is usually very challenging for the data scientists as they are often limited by time and other practical considerations, which do not allow them to try out multiple models simultaneously. Here AutoAI helps them in many ways. Once the models are trained, they can be reused for testing and further tuning in the case of AutoAI.
One crucial aspect is hyper-parameter training that contains the data that govern the training process. Hyper-parameter tuning is done by running the whole training job. The results are evaluated, and adjustments are made to find the best combination of parameters to lead towards the solution.
AutoAI provides a smart, hyper-parameter tuning possibility, which is not just a brute force way but centers around tuning the most important hyper-parameters for each algorithm. The methods used for HPO include evolutionary algorithms, reinforcement learning, Bayesian optimization, etc. It searches through a different range of values for each parameter, and once the algorithm has finished its execution, you can select the corresponding model and visualize the results.
Interpretation and Visualization
You would like to be able to visualize the dataset as well as models, for example, to be able to see the statistical information about the data such as data types, distribution, outliers, and more. Without automated AI, it could take data scientists hours and even days of work. The visualization helps users to get a more intuitive overview and understanding of the data. It allows for interpretation of the models, which turns them into white boxes. For example, it is nice if you could plot the structure of the decision tree visually. That would help the users to evaluate the model and modify the structure of the tree, such as pruning and boosting. Similarly, it helps to have information about the features, their importance, and how do they influence the model predictions.
Model deployment and monitoring
Having the possibility to use the one-click deployment of the models' functionality when the models are ready to be deployed puts the data scientists at great ease and comfort. Furthermore, it helps to select and save services that you would like to be deployed with the model and create versioning of the models. I mean, who wouldn't like to have “git” in there! The automatic scoring of the model pipelines makes the model have everything needed to run them in production. It also gives the users flexibility to run several experiments such as A/B testing, health checks, maintenance, and applying security patches.
The Future of AutoAI
In the future, AutoAI will gain more adoption as well as momentum. It demands further improvement and the addition of capabilities to AutoAI systems. For example, adding the data collection capability would greatly help as it is usually one of the challenging problems to solve, especially high-quality data. This problem has two solutions: 1) data synthesis and 2) data search.
Data Synthesis
Qualitative Data availability is one of the great challenges that we have today. Data synthesis would be a great step for advancing the state of AutoAI. Its manifestations include but are not limited to having data augmentation for image data, translation for textual data, and data simulation.
Data Search
The internet offers huge data; there is a possibility to leverage data search across the internet to empower AutoAI to acquire data for training and validation. Ignoring the complexity and scale of internet data for the sake of argument, it is likely to turn out as a good solution once we can achieve that. Besides this, the focus could be oriented towards making domain-specific use cases and capabilities automated, which would result in a great starting point to advance the business adoption of AI and Data Science.
Continue the conversation
To learn how to kick-start your data science project with the right expertise, tools and resources, the Data Science and AI Elite (DSE) is here to help. The DSE team can plan, co-create and prove the project with you based on our proven Agile AI methodology.
Request a free consultation: ibm.co/DSE-Consultation
Visit ibm.co/DSE-Community to connect with us, explore our resources and learn more about Data Science and AI Elite.
#ai#AutoAI#Featured-area-2#Featured-area-2-home#GlobalAIandDataScience#GlobalDataScience#Highlights#Highlights-home#ML