Hi Thomas,
Thanks for your answer. I posted my question in #ai-governance-support too.
And I have additional question.
I have got multiple requests from customers that they want to retain endpoint url of the deployment even if they update current model by retraining.
As far as I understand, the only way to do this is changing 'Associated asset' of the deployment to the updated model via UI or client.deployments.update() in a notebook.
When I do this, deployment is moved to under the new model in the use case screen and 'Evaluated' tag changed to 'Pending Evaluation'.
And I also see that subscription information is not updated accordingly (It still has old model id when I checked with client.subscriptions.get())
So I updated model information using client.subscriptions.update() like below.
patch_document=[JsonPatchOperation(
op=OperationTypes.REPLACE,
path='/asset/asset_id',
value=new_model_id
)]
response = wos_client.subscriptions.update(subscription_id=subscription_id, patch_document=patch_document)
But model information in Openscale UI is not changed.
Even though I evaluated the deployment again with new feedback data, "Pending Evaluation' tag is not changed and no evaluation information is displayed.
Do you have any idea how to handle this customer's requirements correctly?
------------------------------
Ji Hun Kim
------------------------------
Original Message:
Sent: Thu April 20, 2023 03:04 AM
From: Thomas Hampp-Bahnmueller
Subject: What's the best practices for tracking ML models with the factsheets ?
Hi Ji Hun (I hope that is the right way to address you) -
Additional, updated versions should be tracked as new, separate models, not as revisions of the previous model. Revisions are helpful for snapshoting but not helpful for version tracking because revision numbers are only stable within one project or space.
So, just create a new model for the new version (in the same or even a different project) but then track it under the same use case as the previous model. You will see that a new row will show in the UI with the new model in the "Develop" column. When you then start deploying and monitoring the new version you will see the clones of the new model appear und "Test", "Validate" (preprod) and "Operate" (prod).
Basically each version will show as a separate row in the UI. As a recommendation you can add a version indicator in the model name. You should end up with a situation like the one below for two versions:
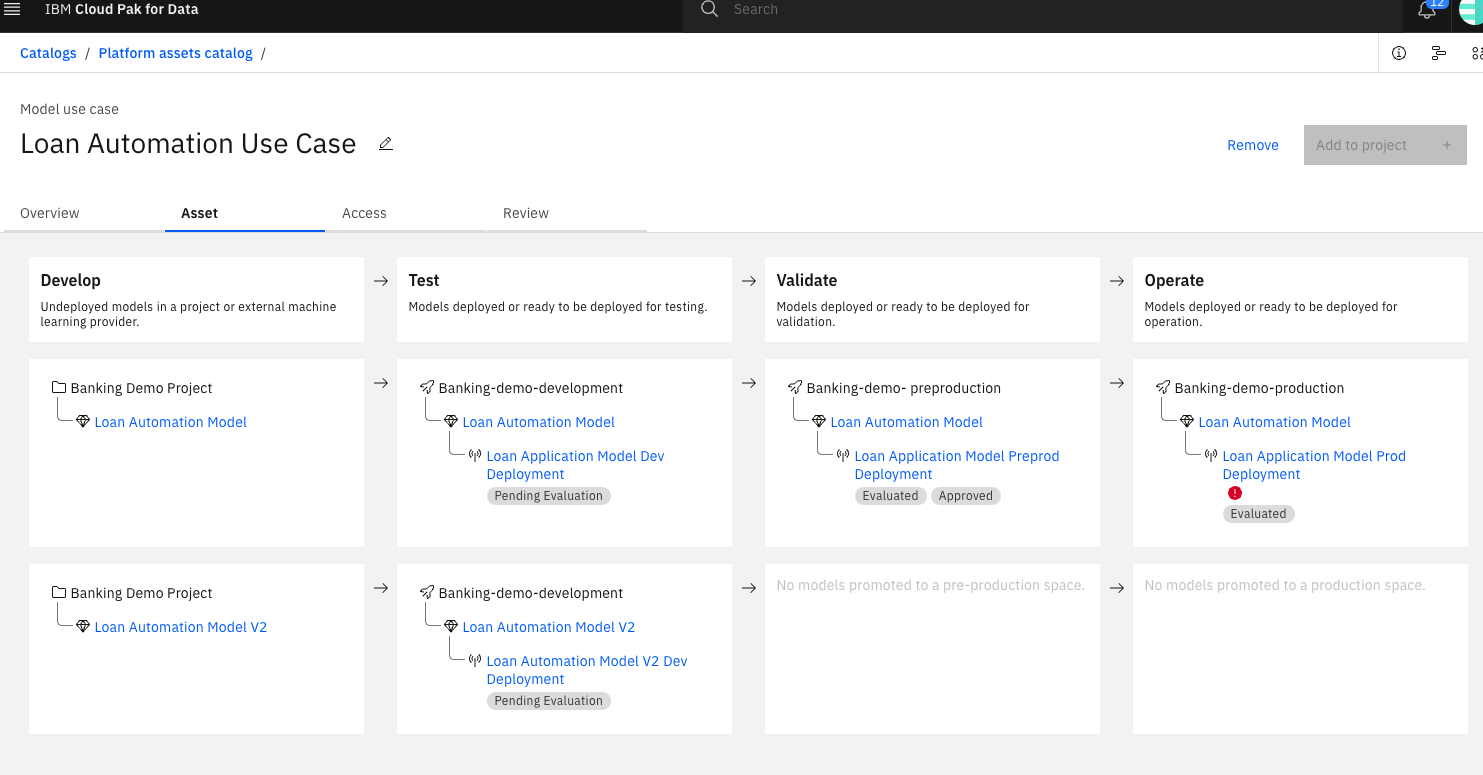
In CPD 4.7 we will had much nicer and richer ways to add version information and information about different approaches attempted to address the same use case.
BTW: If you have access to the IBM intranet you can also ask questions like this (and find answers from others) in the #ai-governance-support Slack channel within the "IBM Data and AI" area.
------------------------------
Thomas Hampp-Bahnmueller
Original Message:
Sent: Wed April 19, 2023 09:55 AM
From: Ji Hun Kim
Subject: What's the best practices for tracking ML models with the factsheets ?
Hi all,
I have some questions in using Factsheets service.
I'm trying to define Model Ops workflow with Factsheets, WS, WML and WOS services on CP4D 4.6.x.
Based on 'Data fabric tutorials' described in https://www.ibm.com/docs/en/cloud-paks/cp-data/4.6.x?topic=tutorials-build-deploy-model,
I deployed models in pre-production and production spaces with following steps.
Save model in the project -> deploy it to pre-production space -> subscribe with pre-production type in openscale => configure monitors => evaluate with payload and feedback data.
-> deploy same model to production sapce -> subscribe with production type in openscale => configure monitors => evaluate with payload and feedback data.
Now model is operating in business logic like shown in below picture.
My question here is what if customers want to retrain this model and replace current deployment in operation ?
- Where should I save updated model ? Save it in the project or in the space ?
- Should I save it with different model asset or update existing one ?
- If I update existing model asset in the project saveral times , can I promote the specific revision to the space ?
- When I promote specific revision from project to the space, should I update existing model asset or create new one in the space ?
I wonder what's the best practice for customers to manage tracking information easily using the Factsheets.
Could you please let me know your recommendation ?
------------------------------
Ji Hun Kim
------------------------------