We’ve all understood the importance of AI Governance in today’s world where trust in AI is more important than ever. And given big data and even bigger use cases, the scale of data being processed and consumed is increasing day by day.
Big corporations have built many AI models on the data they own to solve their business problems and challenges. And these models mostly are batch scoring models that take huge amounts of data at a time and provide the output.
Watson Openscale now also helps in the AI Governance of your batch scoring models, where you can monitor the models’ performance in terms of fairness, drift, explainability and quality.
The first step would be to generate the configuration artefacts to be used using the training data. This can be done using the notebooks available here.
Let’s say you’re using Hive for your data storage then the steps for generating the configuration artefacts would be as follows:
Step 1:
In the notebook, set the flags as True for the monitors, you want to analyse in your model deployment.
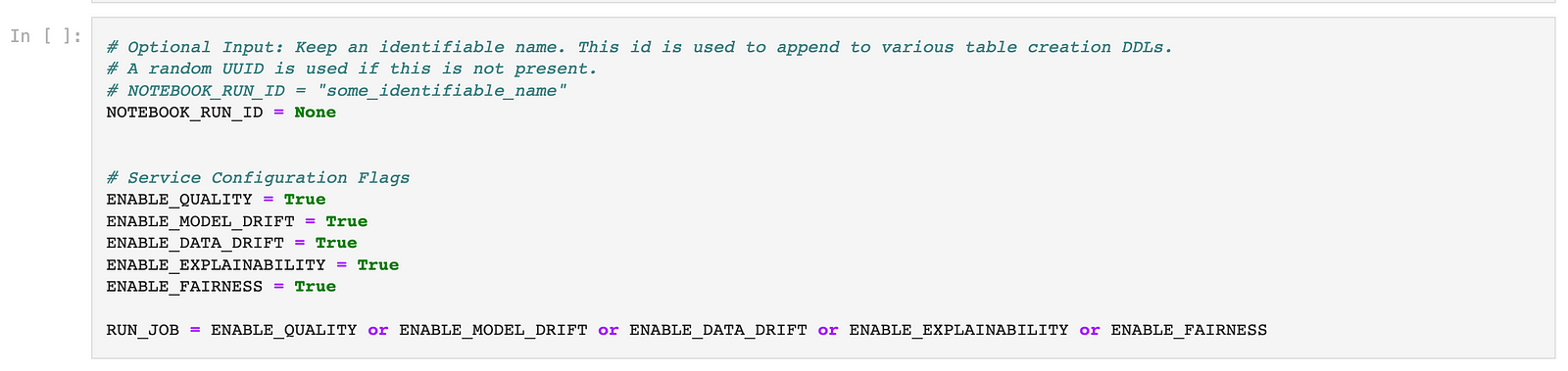
Step 2:
Select your storage type and read the scored training data into the notebook using the following cells:
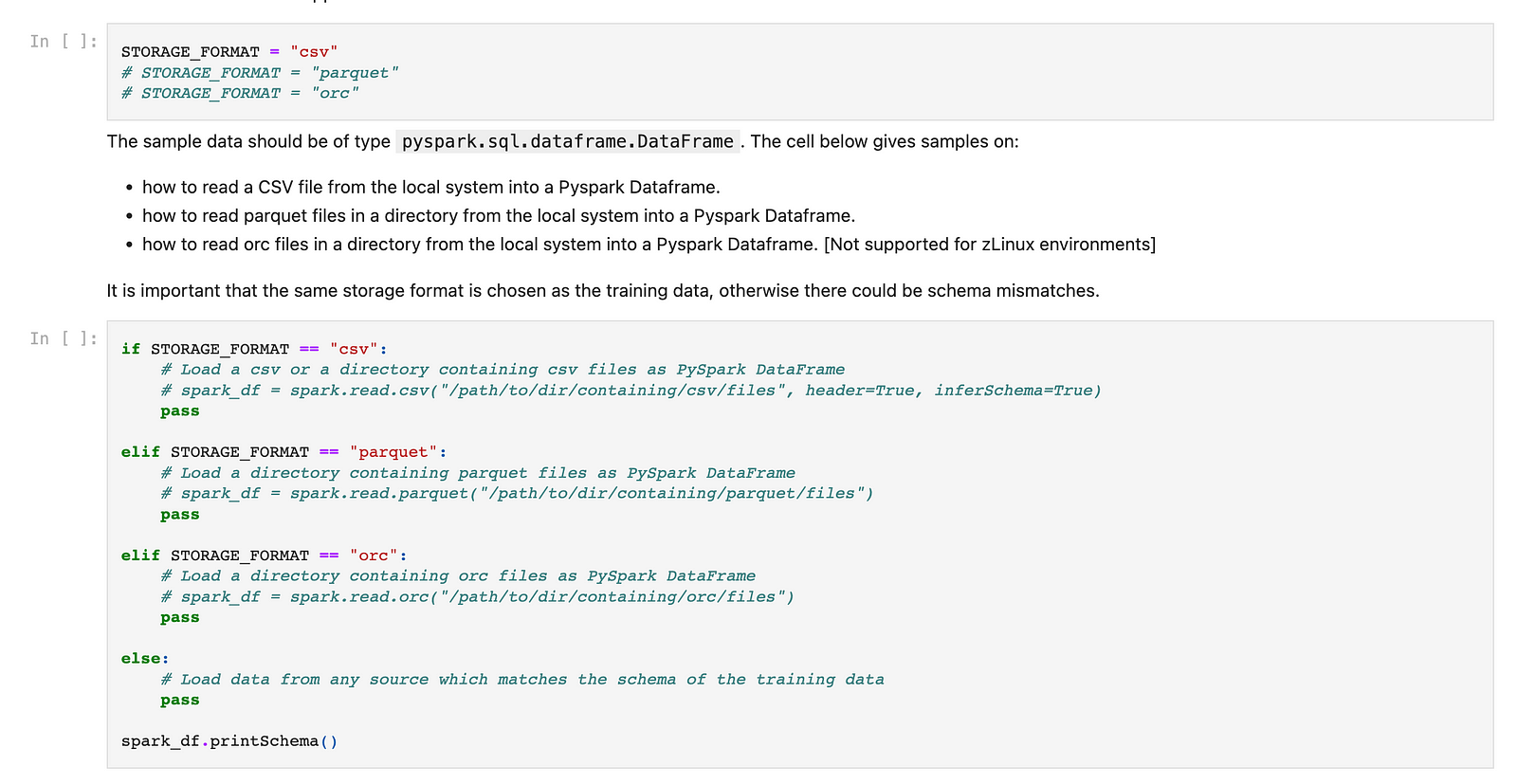
Step 3:
Specify the model type and other model deployment metadata in the following cells:
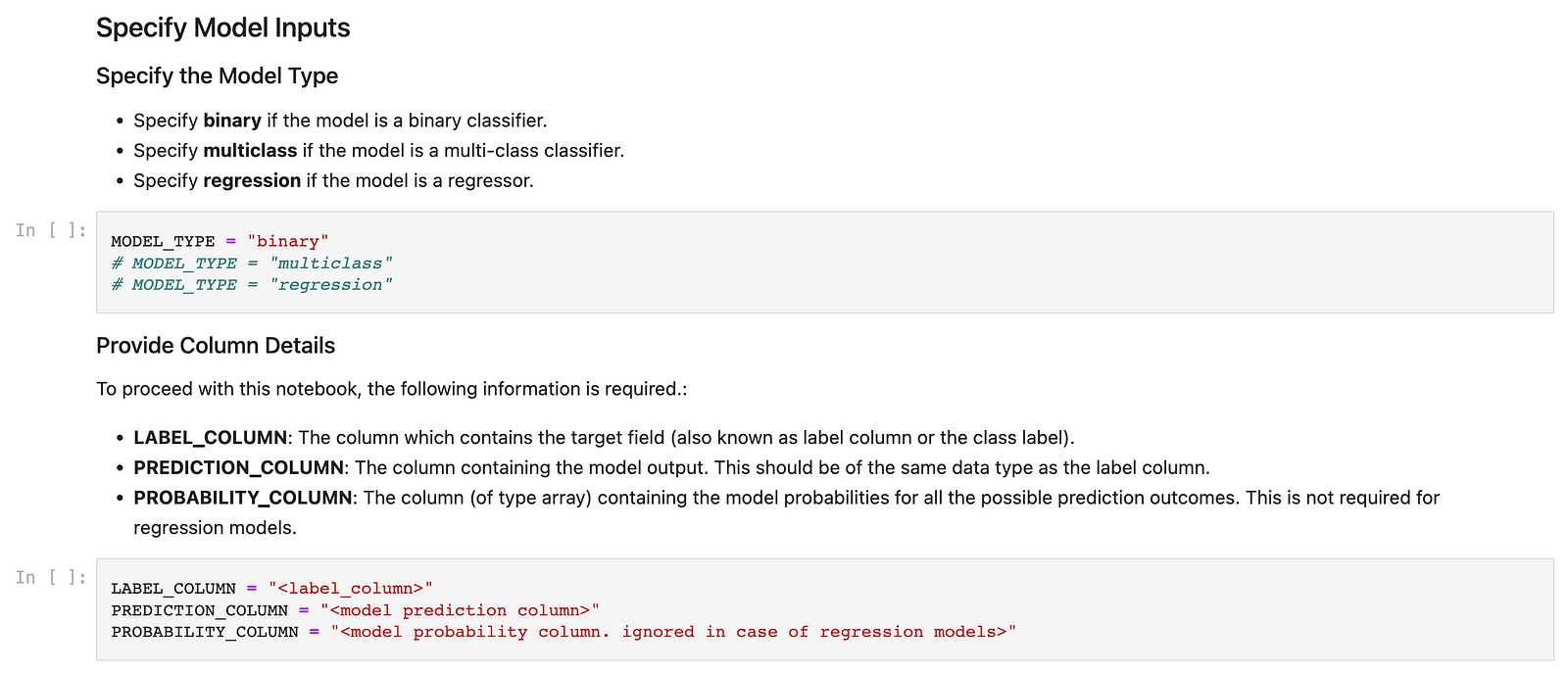
This will generate a common configuration required to create a subscription in Watson Openscale. The following cells would provide you with DDL commands to create the scored training data table, the payload logging and feedback tables in your Hive given the database name, location of data in your HDFS directory and any other table properties you might want to add.
Step 4:
Provide the details of your Spark environment or IAE (IBM Analytics Engine) along with your Hive meta-store details in the following cells.
Step 5:
The following cells would then allow you to provide the Drift and Fairness monitor configurations given that you’ve enabled them at the start of the notebook to be monitored.
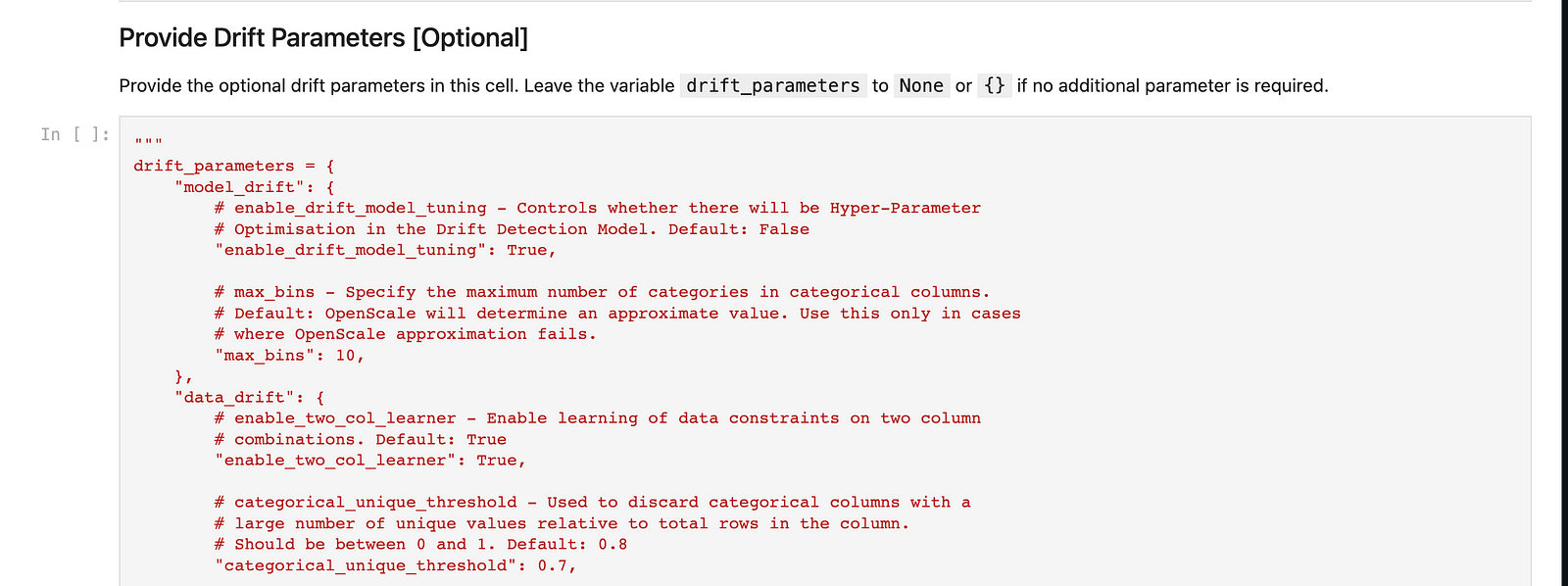

The following cells would then run a Spark job to generate the artefacts for your subscription configuration in Watson Openscale.
Post which, you can download the configuration JSON and the Drift archive using the following cells:
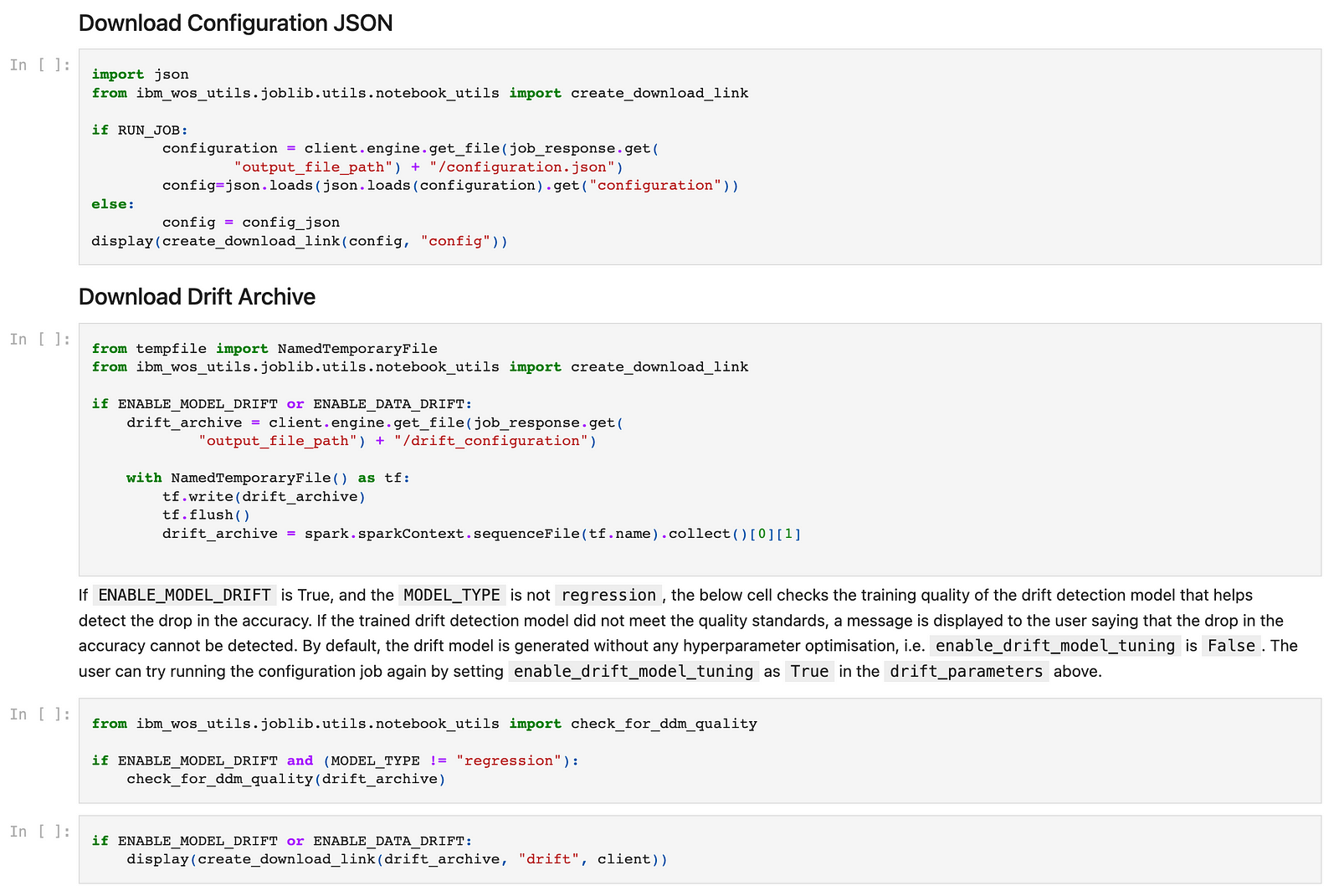
Step 6 (Only if Drift is enabled):
The following cell in the notebook would then give you the DDL command to create the table for drifted transactions in your Hive environment where Openscale would write the said records.

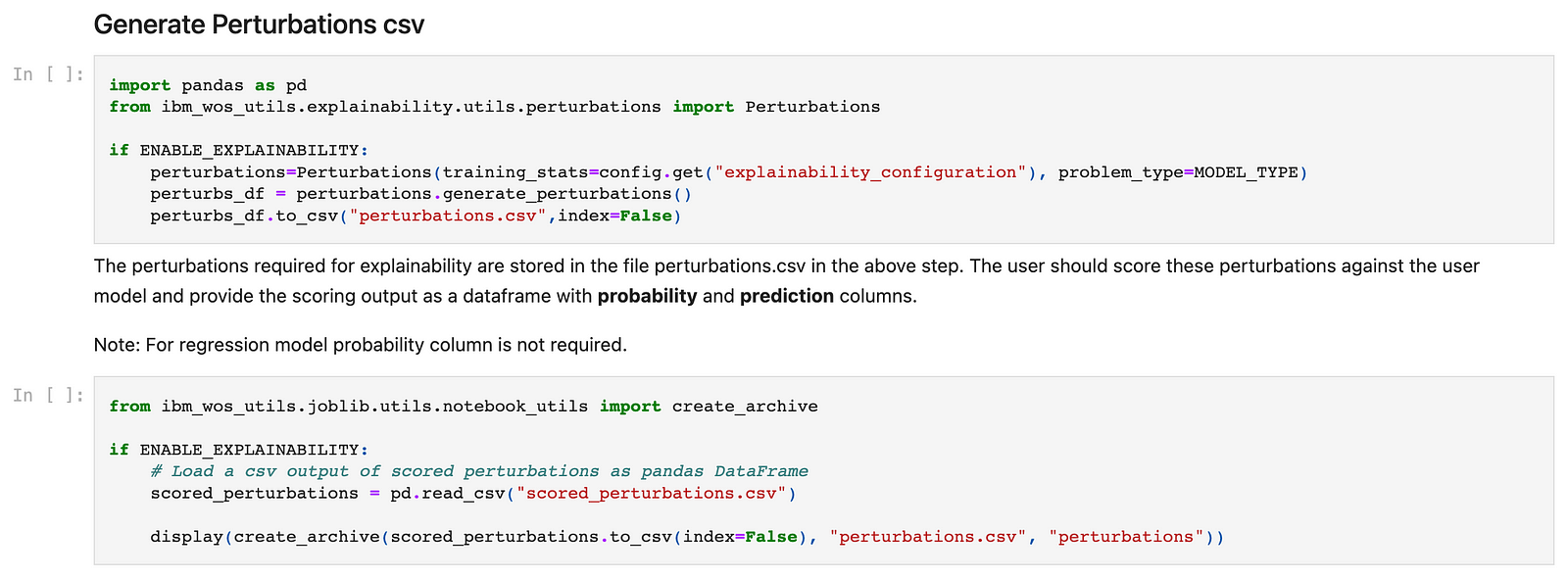
Step 7 (Only if explainability is enabled):
The pre-requisite for the explainability feature to work is to have some scored perturbed records available to be able to generate explanations, hence the following cell would allow you to download a CSV file containing perturbed records which you need to score, and then read again in the notebook in the following cell which will generate an archive to be download to be used in the Openscale dashboard while configuring explainability.
After this, the cells would provide you with DDLs to generate the explanations queue table and the explanations table where the former would have the records on which the explanations are to be generated and the latter would store the corresponding explanations.

The initial process of generating the configuration artefacts is completed. Now we can move on to the Openscale dashboard where we’ll start by adding a batch subscription with the help of the artefacts generated by the notebook above. Detailed steps for the same along with screenshots are available here in the documentation.
Good luck with your model and feel free to play around with fairness, explainability and drift with the pre-production workflow as well. :)
#CloudPakforDataGroup