Generative AI (GenAI) offers many powerful capabilities straight out of the box. By responding to user prompts, a large language model (LLM ) can generate new content, such as drafting customer emails or contracts or assisting with code generation. It can summarize key information from long-form content, such as reports and videos, and it can extract and classify information from a large number of documents, making it a versatile tool that significantly enhances enterprise productivity.
However, in order to harness GenAI to reason or think, make decisions, or perform coordinated tasks, you need to do more. You must create a more complex architecture around your LLM, integrating additional tools or resources and coding specific policies. Below are three examples.
-
Use RAG to Drive Accurate, Contextual Responses
RAG, which stands for Retrieval-Augmented Generation, is a way of enabling an LLM to generate accurate answers or content about specialist or niche topics that may be external to its training data.
Imagine an LLM with access to a company’s customer service knowledge base, product catalogue or technical product manuals. This would allow it to generate accurate, contextually relevant answers to specific questions augmented by this company-specific information. RAG implementations like this are perfect for customer service chatbots or providing support and training to field service engineers.
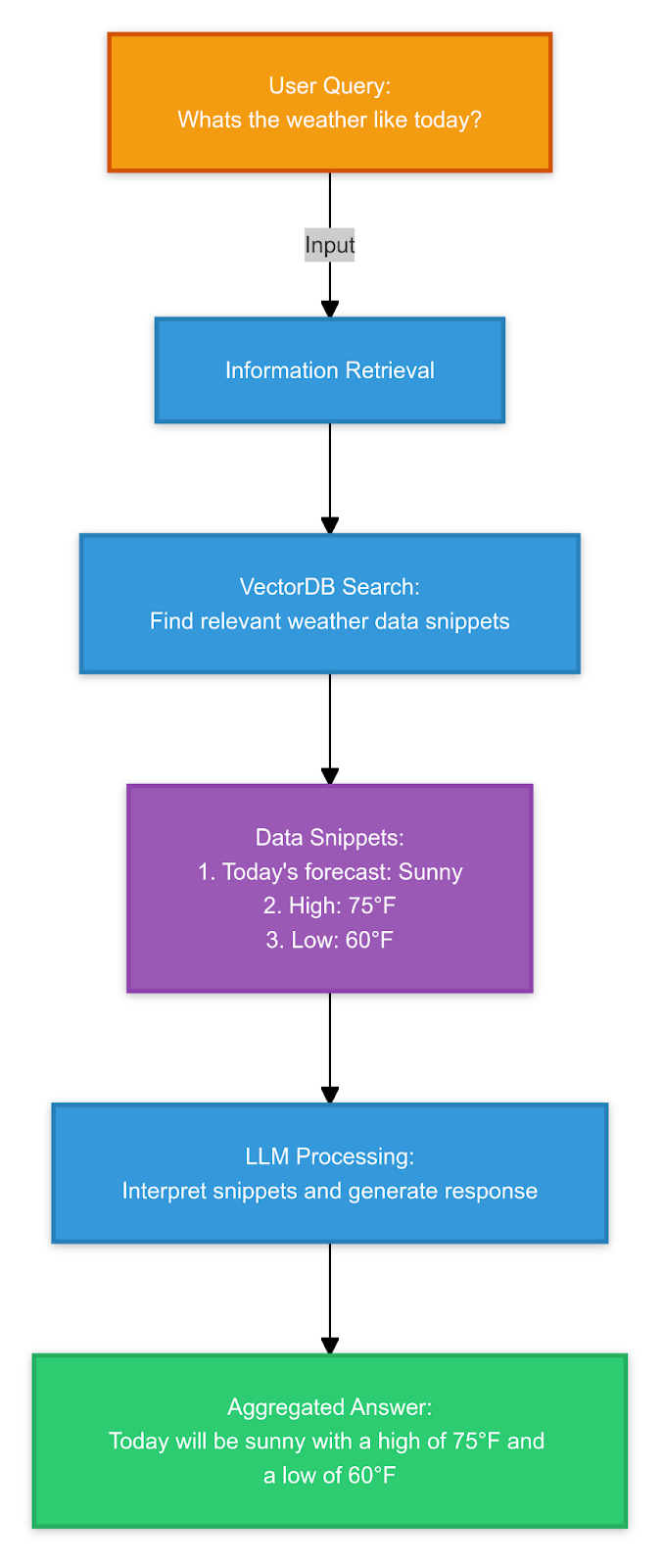
Below is a diagram of a RAG framework deployed as part of a semantic search application that will tell users the weather forecast in their area. This application gives an LLM access to a specialist continuously updated weather information database. In response to user queries, the system can search and retrieve weather information from the database to generate relevant, accurate natural language answers.
The system utilizes a vector database to index the information from the original database, enabling semantic searches to find the relevant information in response to a user’s question. A knowledge aggregator combines information from the database and LLM to provide comprehensive answers.
-
Use RAG to Drive Accurate, Contextual Responses
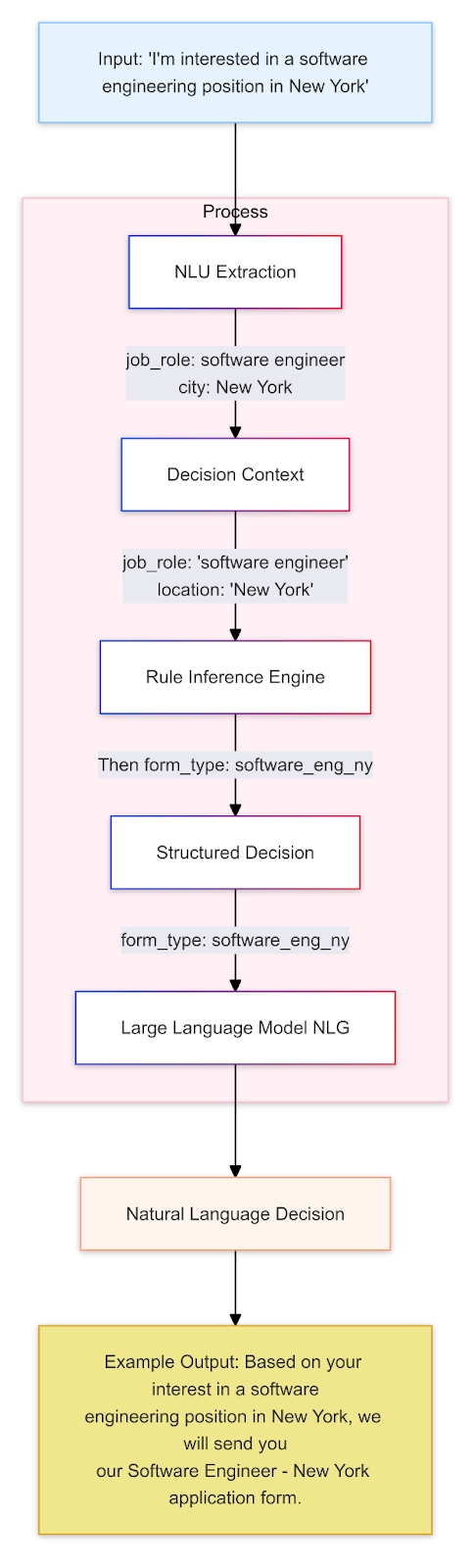
One approach to using GenAI to display reasoning is to create an architecture that enables it to make decisions based on structured data and a rules engine. This involves using an LLM’s Natural Language Understanding (NLU) capabilities to extract entity information from a user input or request and then using the rules engine to make decisions based on the extracted data.
The diagram below illustrates this with the example of a recruitment company processing incoming plain-text emails from job applicants. The LLM extracts required entity information, such as ‘city name’, ‘job role’, etc., from all incoming emails, which is then fed into a rules engine. The rules engine can then determine the appropriate job application form to send to each potential applicant.
Another example would be a customer-facing banking chatbot that uses conversational AI. The LLM can extract required entity information, such as ‘show me my bank balance,’ and use the rules engine to determine whether the customer should be shown their on-screen balance.
The beauty of using the NLU capabilities within an LLM to extract entity information is that they are trained on a vast data set. This allows it to recognise and interpret variations in language, including different phrasings and even spelling errors. An LLM can intuitively understand patterns, which means it can extract entities even if the customer says, “How much money do I have in my account?” instead of “What is my bank balance?”

-
Use your LLM to Drive a Workflow
GenAI can drive a workflow, for example, by acting as a central hub that gathers information from multiple sources, processes it, and generates actionable responses or notifications.
In the diagram below, the LLM triggers an email or a task notification or work summary to an employee after receiving information from two internal business systems.
Imagine a use case in which one source of information is a company’s CRM system that tracks all customer requests for online product demos scheduled for the upcoming week, including specific demo requirements and customer contact details. The other source is an internal calendar that shows not only the availability of the company’s expert product demonstrators for conducting those demos during that same week but also their areas of expertise and preferred time slots. The LLM can gather and analyze information from both sources to generate personalized notifications or emails, prompting available product demonstrators to reach out to customers, schedule a demo, and prepare accordingly based on the customer's specific needs and the demonstrator's expertise.
In the finance sector, an LLM can streamline the invoicing process by automatically generating and sending invoices after cross-referencing inventory management and customer databases. Given the sensitive nature of business data, it's crucial to implement robust security protocols, such as encryption and access controls, to protect the information processed by the LLM.
Looking ahead, LLM-driven workflows are expected to become even more sophisticated. Emerging technologies like AI-driven predictive analytics could be integrated with LLMs to forecast workflow needs and proactively allocate resources.
Conclusion
By adding additional resources and policies and developing a structured architecture, it is possible to go way beyond what an LLM can do straight out of the box. As enterprises become more familiar with the possibilities, expect to see them develop innovative, practical applications to get more out of GenAI.