Authored by: Jitendra Singh, Rishika Kedia, Holger Wolf, Niha Tahoor M
Abstract: This blog talks about the various log storage options supported by Loki. As Loki is an alternative to Elasticsearch. In this blog, we'll take a closer look at the supported storage options for Loki in Red Hat OpenShift on IBM® Z® and IBM® LinuxONE.
Introduction
The Cluster Logging Operator is a Red Hat OpenShift component that provides a unified logging solution for containerized applications running on Red Hat OpenShift clusters on IBM Z / IBM® LinuxONE, and others. It allows administrators to collect, store, and search logs from multiple sources within a Red Hat OpenShift cluster. It aggregates all the logs from your Red Hat OpenShift cluster, such as node system audit logs, application container logs, and infrastructure logs and stores them in a default log store. It supports several storage options for storing logs, including Loki.
Loki is a popular open-source log aggregation system that allows you to store, search, and analyse logs in a distributed environment. Loki uses a microservices architecture and can be deployed on Red Hat OpenShift using the Loki operator. When it comes to storage, Loki operator supports several storage options that you can choose based on your needs.
Loki Storage Architecture
Loki's storage architecture is based on the concept of "index-free" logging. This means that instead of indexing logs by their content, Loki indexes them by their metadata, such as the source, labels, and timestamps. Loki stores logs in chunks, which are immutable blocks of data that contain a set of log lines. Each chunk is compressed and stored on disk in an object store. Following are the storage options listed that can be used with Loki operator.
Advantages of storing in object storage
There are several advantages to using object storage for Loki in Red Hat OpenShift Cluster Logging:
- Scalability: Object storage can store large amounts of data and can scale to petabytes or even exabytes, making it ideal for storing massive amounts of log data generated by Red Hat OpenShift clusters.
- Durability: Object storage typically stores multiple copies of data across multiple data centers or availability zones, making it highly durable and resistant to data loss.
Cost-effectiveness: Object storage is typically less expensive than block storage, especially for storing large amounts of data over long periods of time.
- Accessibility: Object storage can be accessed from anywhere with an internet connection, making it easy to share data across different regions or with remote teams.
- Integration: Object storage can integrate easily with other cloud services and tools, such as backup and disaster recovery services, making it a flexible and versatile option for storing and managing log data.
- Security: Object storage typically provides built-in security features, such as encryption and access controls, to help protect data from unauthorized access or data breaches.
Overall, using object storage for Loki in Red Hat OpenShift Cluster Logging can provide a highly scalable, cost-effective, and durable solution for storing and managing log data generated by Red Hat OpenShift clusters, fitting very well to a Red Hat OpenShift cluster running on IBM Z and IBM® LinuxONE.
The following sections will describe the installation instructions for the supported options.
1. Supported storage options for Loki Operator in Red Hat OpenShift
Loki operator in Red Hat OpenShift supports several storage options, including Red Hat OpenShift Data Foundation (ODF) that is now called IBM Storage Fusion Data Foundation when purchased from IBM, MinIO, Amazon Web Services S3 (AWS), Microsoft Azure, Google Cloud Storage (GCS), and Swift (OpenStack Object Store) for object storage.
IBM Storage Fusion Data Foundation and MinIO can be installed on IBM Z / IBM® LinuxONE.
Note: In this blog, we do not cover Mircosoft Azure and Swift for object storage.
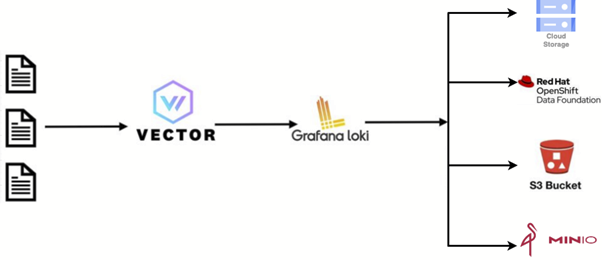 Figure 1: Workflow from log collection to storing it
Figure 1: Workflow from log collection to storing it
1.1 Red Hat OpenShift Data Foundation (ODF)
1.1.1 Red Hat OpenShift Data Foundation installation and configuration
Deploy the Red Hat OpenShift Data Foundation on your cluster. See Installation Instructions
Create Storage and storage class to use with it.
After installing and setting up ODF, you will need to create storage to use with it as shown below:
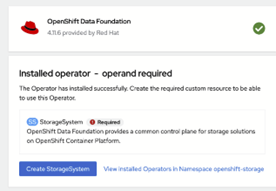
Figure 2: Installation panel in ODF to create storage.
After the appropriate storage creation, the storageclasses are created (see below); we will be using ocs-storagecluster-ceph-rbd.

1.1.2 Use ODF storage to install Loki
Extract ACCESS_KEY and SECRET_KEY to use for creating bucket and secret.

Create Bucket: there is a default bucket named first.bucket, we can use this bucket to work with Loki, besides, we can create our own bucket also.
· Create secret (odf-s3-secret) for Loki stack to connect to the S3 bucket created by ODF:

Create LokiStack referencing secret name and storageclass.
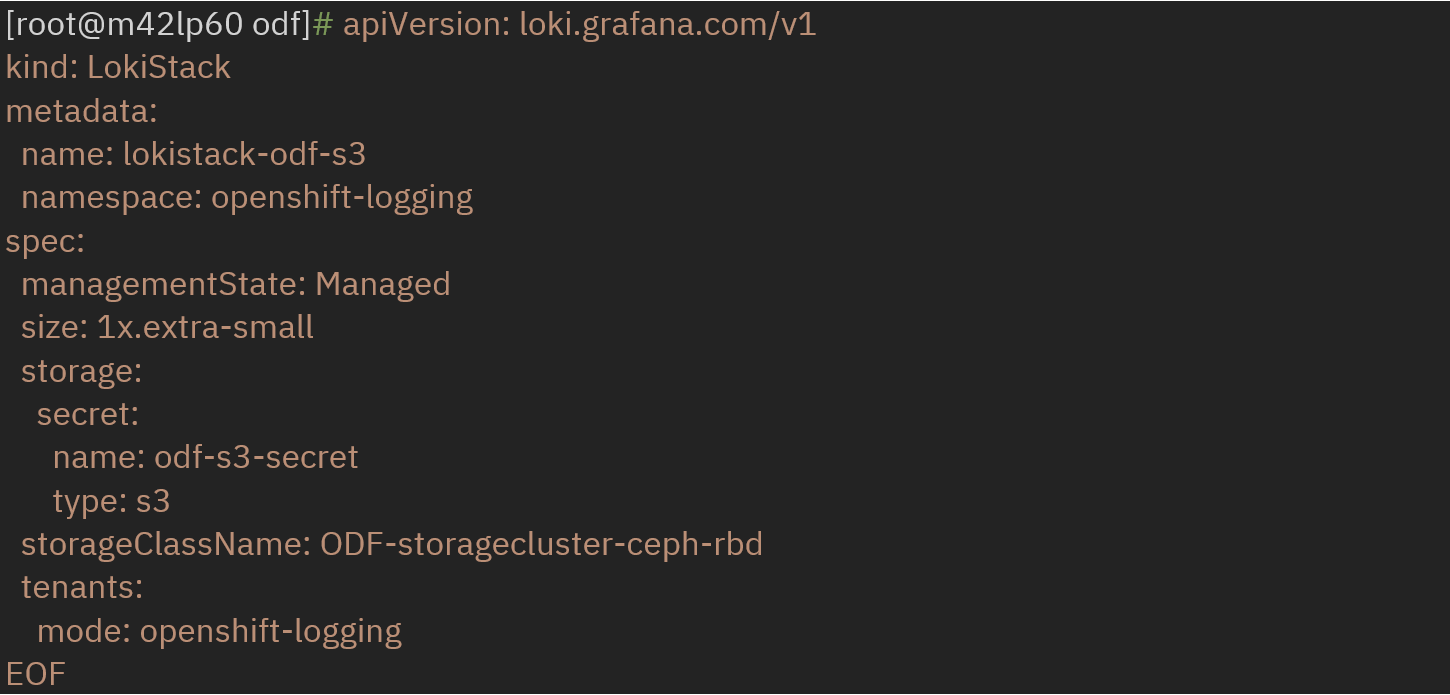
Create clusterlogging instance by referencing above LokiStack.
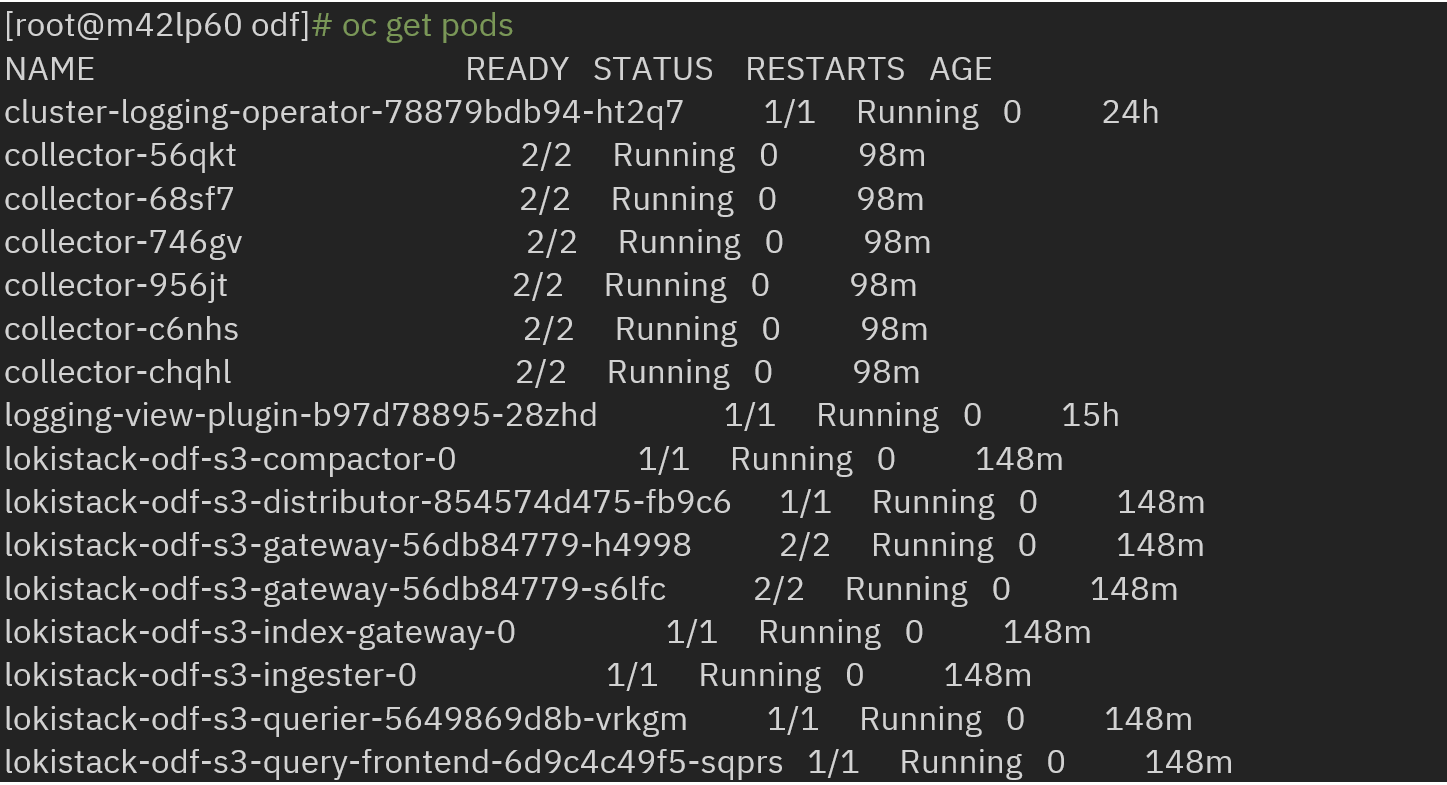
· Logs can be visualized on the console logs panel: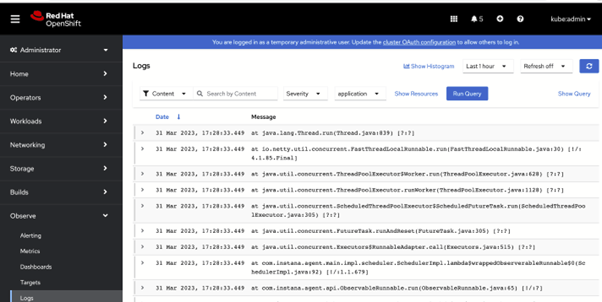
1.2 MinIO
MinIO is a storage solution for objects that offers an API compatible with Amazon Web Services S3 (S3) and encompasses all the essential features of S3. It is designed to be deployable in various environments, whether public or private cloud, baremetal infrastructure, orchestrated environments, or edge infrastructure.
It can be installed and setup on IBM Z / IBM® LinuxONE. The details are available here.
1.2.1 Requirements
· Download and setup MinIO wherever you feel comfortable. As for S390x (IBM Z/IBM® LinuxONE) we have MinIO binary available, and we deployed / setup the binary on our LPAR.
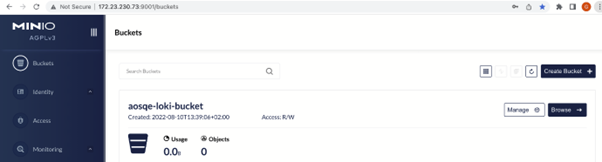
· Create a bucket on MinIO webconsole or CLI. Here we have created our bucket name as aosqe-loki-bucket using console.
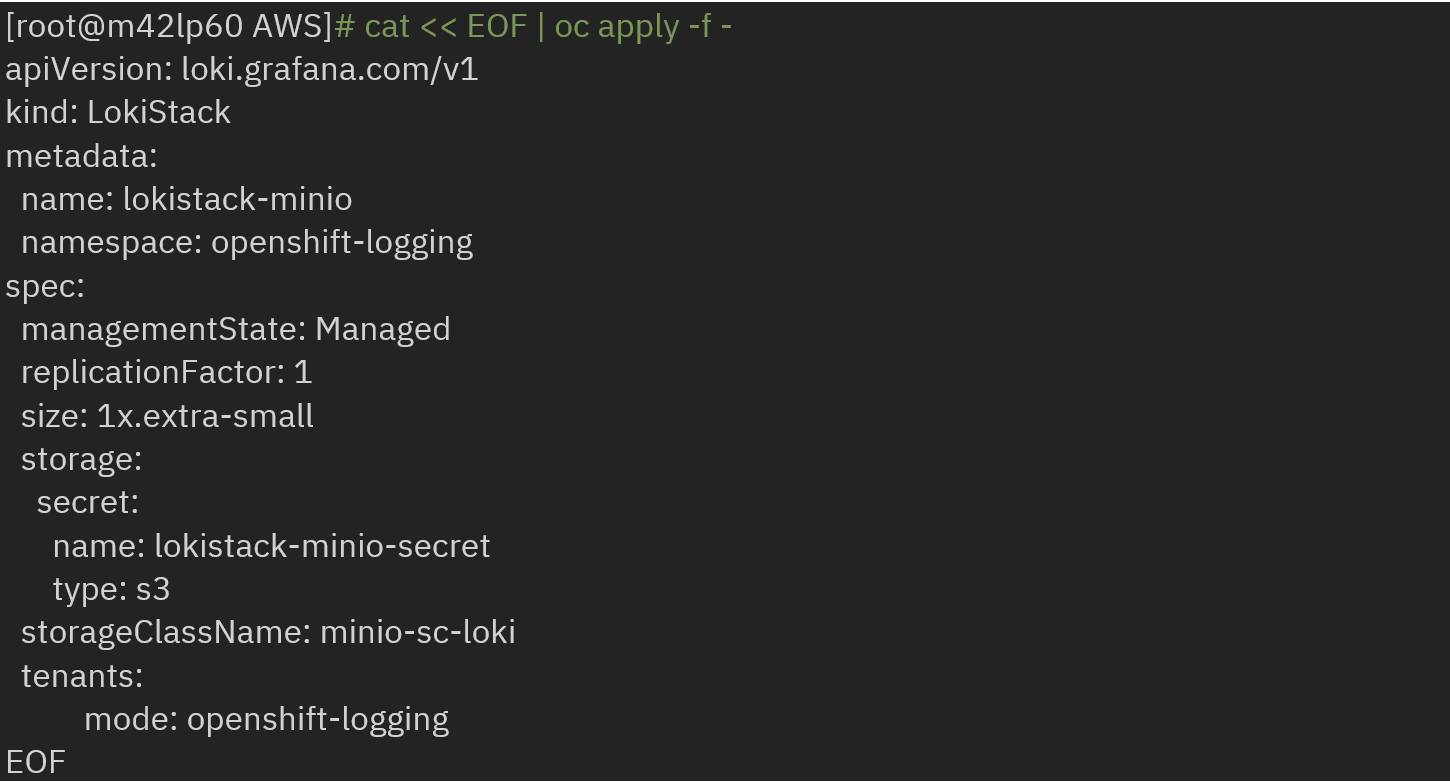
1.2.2 Installation

where lokistack-minio-secret is the secret name.
Create storage class:

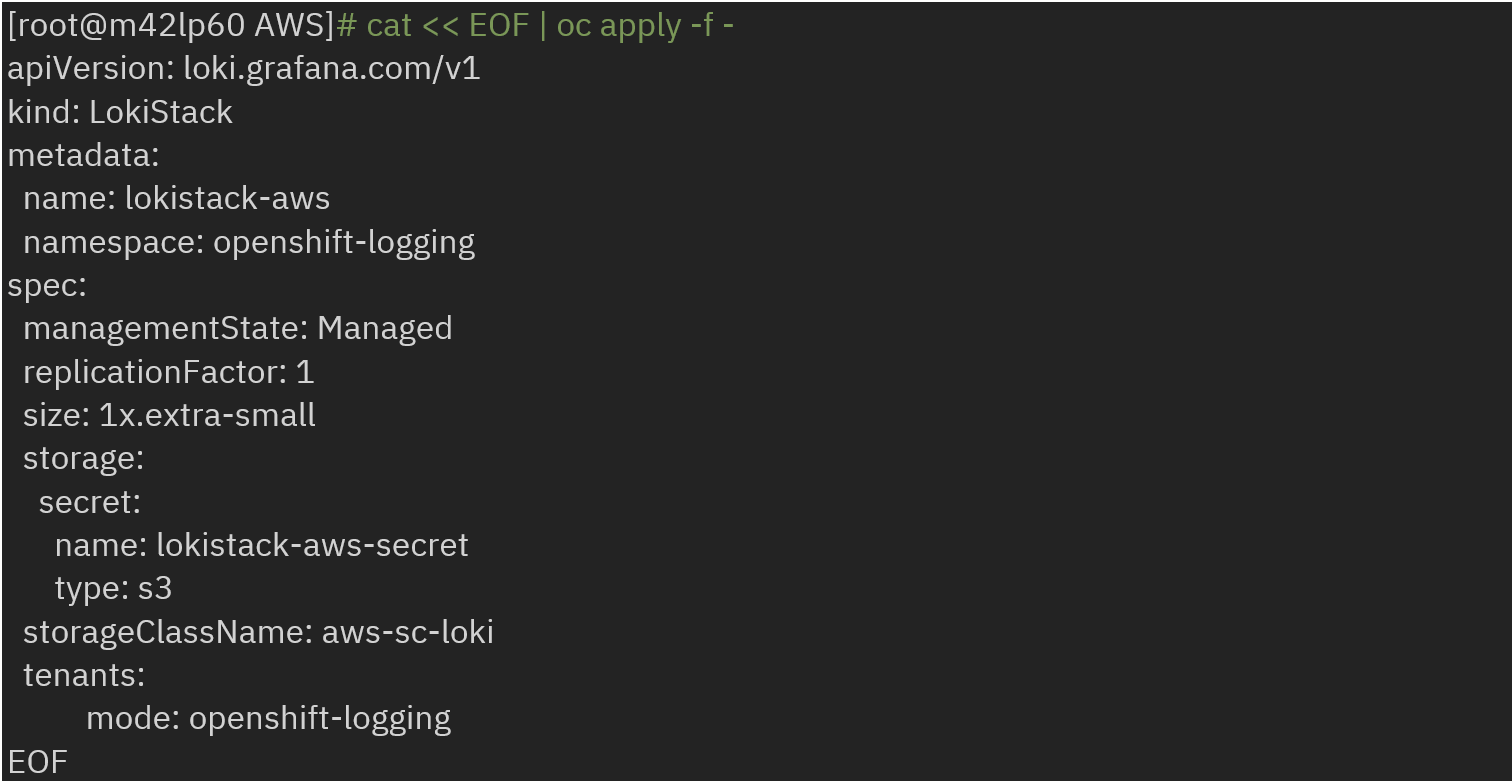
· Create an instance of LokiStack by referencing the secret name, created storage class and type as s3:
1.3 Amazon Web Services (AWS) S3
1.3.1 Setting up storage on AWS
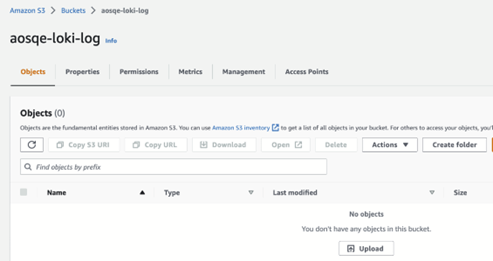
· Create a bucket on AWS.
· Extract/Save ACCESS_KEY and SECRET_KEY from AWS account.
1.3.2 Installation using S3 bucket
· Create an Object Storage secret with keys as follows:

where lokistack-aws-secret is the secret name.
· Create storage class:
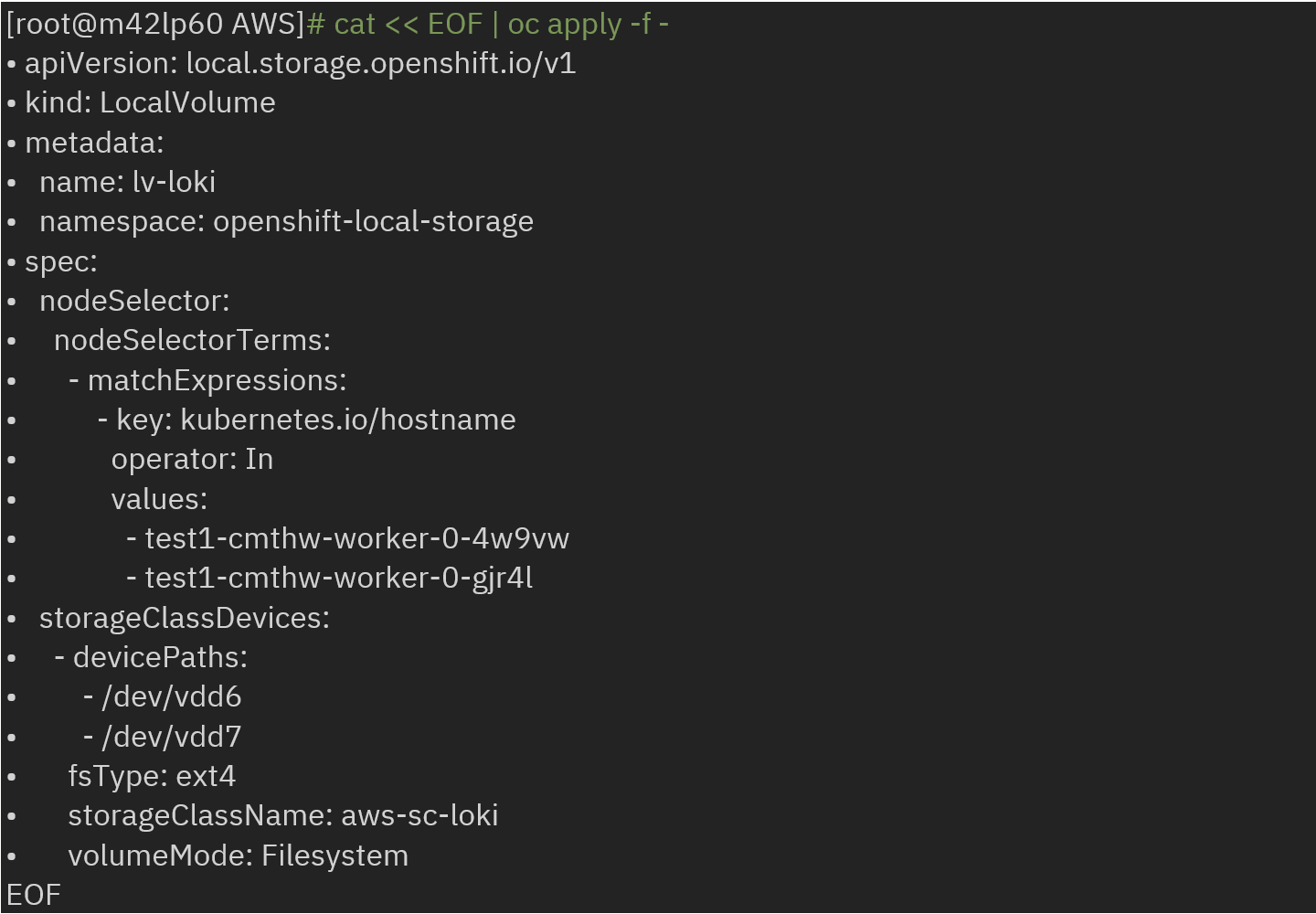
· Create an instance of LokiStack by referencing the secret name, created storage class and type as S3:
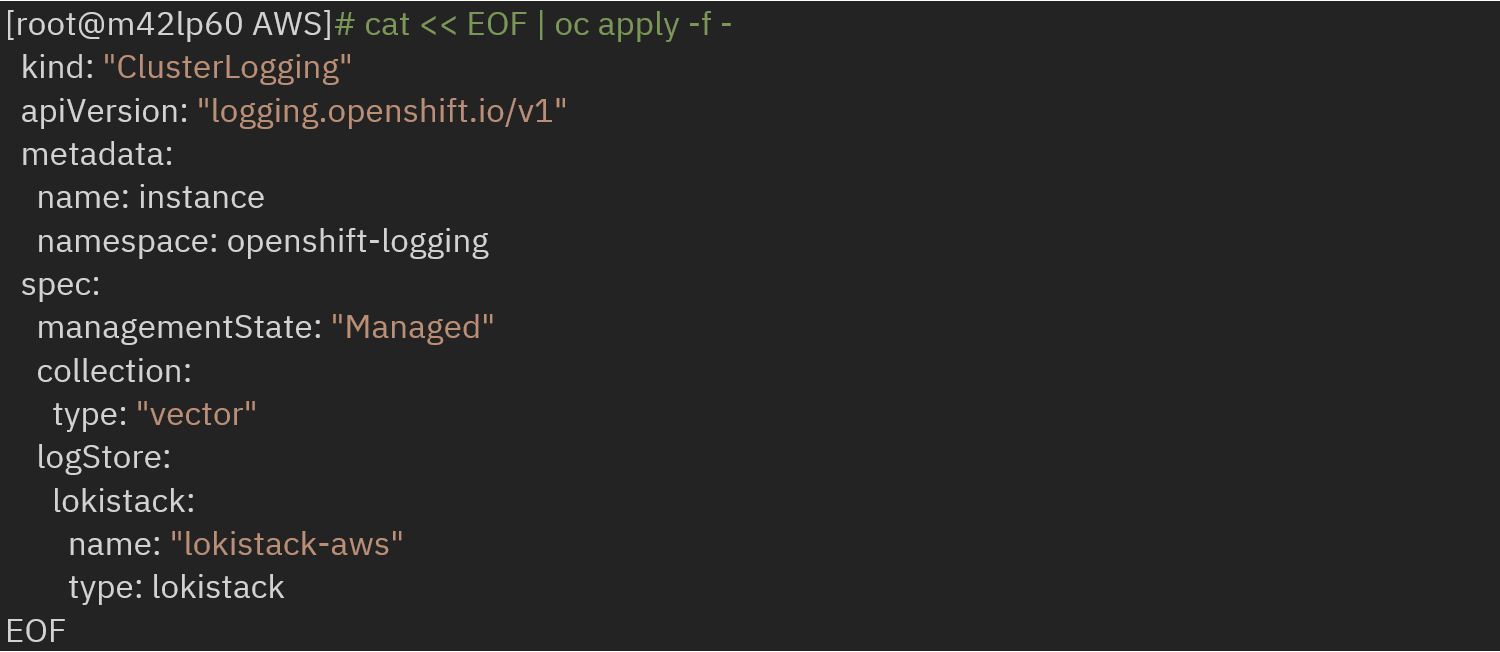
Now, create clusterlogging instance by referencing the created LokiStack and collector as vector:
Log visualization at AWS console:
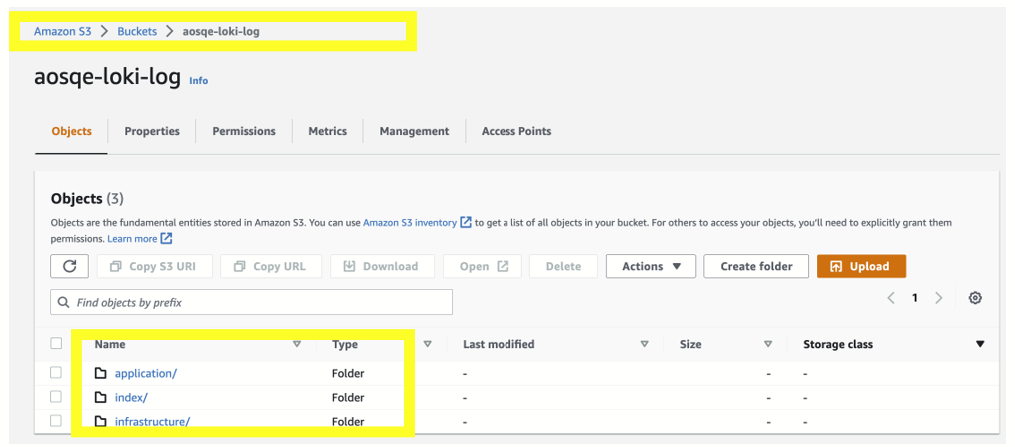
1.4 Google Cloud Storage
1.4.1 Create a project on Google Cloud Platform (GCP)
Create a bucket under same project.
Create a service account under same project for GCP authentication.
1.4.1.1 Installation
· Copy the service account credentials received from GCP into a file name gcp_key.json.
· Create an Object Storage secret with keys bucketname and key.json as follows:

where lokistack-secret-gcs is the secret name, Loki-GCP-bucket is the name of bucket created in requirements step and gcp_key.JSON is the file path where the secret with keys was copied to.
Create an instance of LokiStack by referencing the secret name and type as gcs:
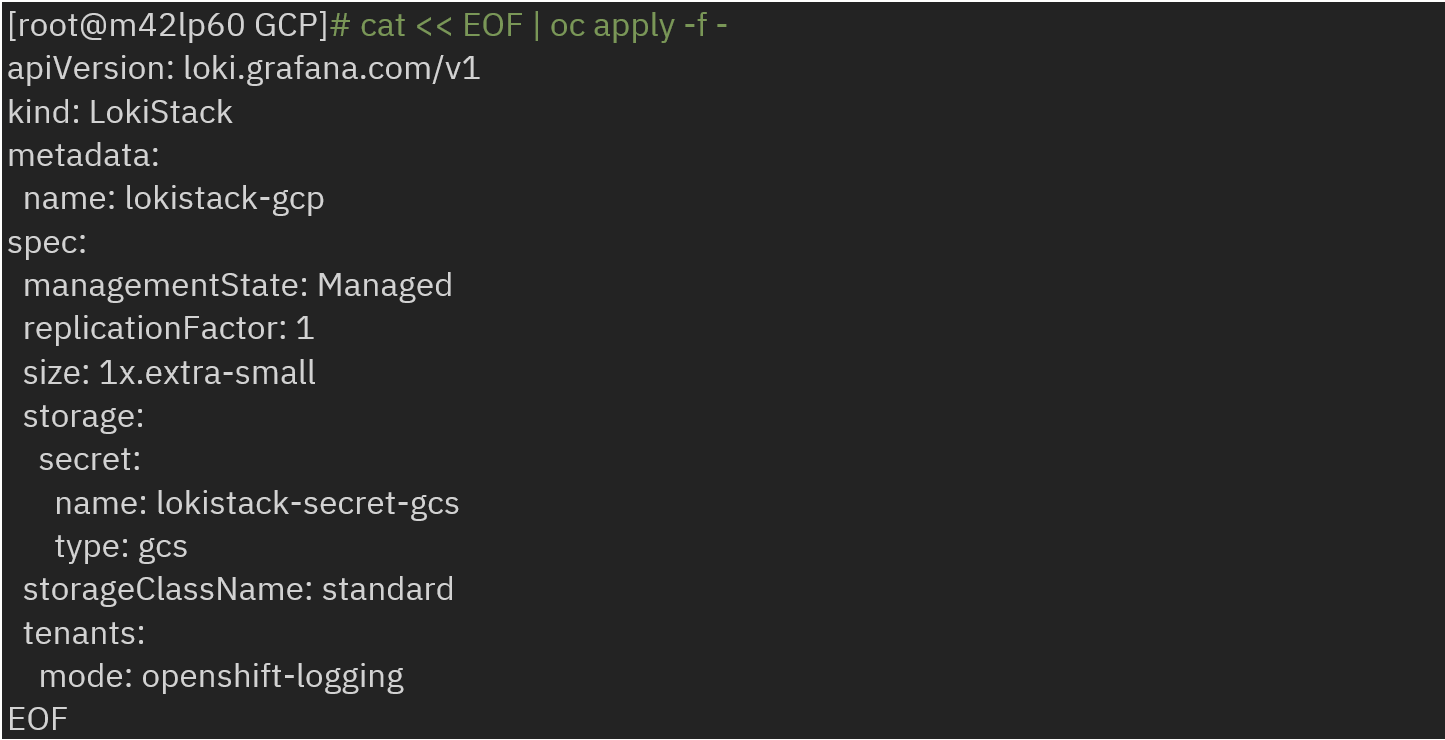
Now, create clusterlogging instance by referencing the created LokiStack and collector as vector.
Conclusion:
Overall, the Loki operator architecture in Red Hat OpenShift provides a scalable, distributed, and fault-tolerant log aggregation system that can be deployed on various storage options, including on-prem on IBM Z / IBM® LinuxONE. The choice of storage depends on your needs, such as durability, scalability, high availability, and cost-effectiveness. By choosing the right storage option, you can ensure that your logs are stored securely, efficiently, and are easily accessible when you need them.
References:
https://docs.openshift.com/container-platform/4.12/logging/cluster-logging-loki.html
https://loki-operator.dev/
https://access.redhat.com/documentation/en-us/red_hat_openshift_data_foundation/4.12
https://min.io/docs/minio/linux/index.html
https://cloud.google.com/resource-manager/docs/creating-managing-projects
https://cloud.google.com/storage/docs/creating-buckets
https://cloud.google.com/docs/authentication/getting-started#creating_a_service_account
https://docs.aws.amazon.com/AmazonS3/latest/userguide/create-bucket-overview.html
