GraphQL APIs with Go on z/OS: A Tutorial and Demonstration
Almost every developer has worked with a REST API in some fashion at some point in their career due to the standard's immense popularity and simplicity. But how many of us have ever considered alternative API designs? There are actually quite a few modern solutions that have advantages over the tried-and-true REST architecture like Kafka, gRPC, and the focus of this blog: GraphQL. Each style has its own benefits and drawbacks, so there is no one API to rule them all. The best way to approach modern API design is to have an understanding of when and why to use each style. In this blog, we will showcase an example case where a GraphQL implementation has measurable performance improvements when compared to a REST counterpart. We will document the whole development process from start to finish as well as provide the tutorial code used. By the end of this blog, you should have another tool in your belt to help you architect sleek and modern APIs.
What is GraphQL?
GraphQL (or Graph Query Language) is a relatively modern way to structure your user-facing API. The specification defines the query language which can be used to write concise queries to a compatible API, similar to the way you can use SQL to interact with a Database. The server will define a schema and all of the types of data that exist within the API. We can then nest and aggregate these types / define how they relate to each other to create complex representations of our data.
To enable this functionality, a server side application will make a single endpoint available that is solely dedicated to GQL queries. Clients then write http requests to this endpoint in a similar way to any other traditional REST API. However the body of this request will contain an object that defines one of two GQL operations.
Queries are simple operations that request data from the API. The server will define what queries are possible, but the client has the power to specify exactly what data will be retrieved and can supply arguments that will modify how the server responds to request. For example, consider a simple query definition that makes all of the data available to the client. By specifying a sample JSON object in the query request (omitting some number of fields that the server-side data would normally be composed of), the sever will respond with data that matches the shape of the input, omitting data that was not requested. We will see such an example later in this tutorial.
A Mutation is any operation that will modify persistent data server-side (As you may have guessed based on the name). We can define these mutations however we please, and they can accept arguments just like the queries from above. Consider a POST request for a traditional REST API. We would supply the object that we wish to send to the server in the hopes that it is stored in a database. Similarly in a GQL API, we can define a "createMyObject()" mutation that could implement the same functionality. We will also see some example mutations later.
This tutorial will only scratch the surface of what is possible with GraphQL, so for more information reference the official tutorial
Why GQL?
A GraphQL API can provide some very powerful features to both its maintainers and consumers. Having an API that complies with the GQL protocol will provide the end-users with a great ecosystem of tools to help write Queries or explore the data that your API has to offer. Check out the GQL website to see the list of supported clients. Its static typing system also makes designing and debugging your API a breeze.
Another great use case for GQL APIs is to reduce the amount of data that is being sent from the server to the client. REST APIs commonly return large JSON objects that can contain many small pieces of information. If a user wanted to only retrieve a small portion of this data, there would be no way to reduce the requested data without the server implementing a separate route or operation that supports exactly what this client is requesting. With GQL, we can simply let the user write their own query to obtain exactly the data they want. We will be demonstrating this use case in this tutorial.
GQL and Go
There are a variety of modules for Go that support both GQL servers and clients. For this tutorial, we will be using gqlgen to implement our server. This module will generate all of the template code we need once we have defined our schema. This module also works out-of-the-box on z/OS as of this date (April 24th, 2023) Here is a feature comparison between a few different modules. (Written by the authors of gqlgen)
Tutorial
The Goal
In this tutorial, we will implement a GraphQL API that wraps a database containing hockey team information. Each team can have many stats associated with it, like Wins, Losses, PowerPlay%, Corsi, and more. A naïve REST example will just make the entire database of teams available to the end user, and will assume that the user can sift through the necessary stats. We would like to instead provide the end user with a GraphQL endpoint that allows the user to specify which stats they would like. Our example case will be a leaderboard, where the only information we actually need is the team name, location, win/loss record and points. If you would like to follow along, all of the code for this tutorial can be found here: REPO LINK.
Installation & Generation
First we will begin by initializing our Go project by executing go mod init and go mod tidy. Then to install the gqlgen module, run go get github.com/99designs/gqlgen. You can now run go run github.com/99designs/gqlgen init to create a GQL template within our project, or go run github.com/99designs/gqlgen generate to re-generate the GQL code after you have made modifications to the schema. Refer to the gqlgen quickstart for more information/configuration options.
We can now see that some code has been generated for us. The directory should look like this:
MyGQLProject/
├─ go.mod
├─ go.sum
├─ gqlgen.yaml
├─ graph/
│ ├─ generate.go
│ ├─ model/
│ │ └─ models_gen.go
│ ├─ resolver.go
│ ├─ schema.graphqls
│ └─ schema.resolvers.go
└─ server.go
server.go contains the driver code that will host our server. We can run this file to see the template in action. gqlgen.yml contains some configuration options that we will ignore for now, and the graph/ directory contains all of our GQL code. Within this directory we see a few different files, the most important being schema.graphqls. This is where we will define our GQL schema, and where the 'generate' command will pull from. Within it we can see the template schema that currently executes when we run server.go.
Defining our Schema
Examining the default schema that was generated for us we can see some common keywords. We can define custom types with the type keyword followed by the name we would like to give it. These are the first two types defined in the example schema:
schema.graphqls
type Todo {
id: ID!
text: String!
done: Boolean!
user: User!
}
type User {
id: ID!
name: String!
}
The rest of a custom type looks similar to a Golang struct where we have the variable names followed by some other data type. GQL provides some primative types for us to start with like Int, String, Boolean, ID, and a few more. We also see that we can reference other custom types within our schema definitions. This allows us to define how these types relate to each other.
We also see the definitions of our queries and mutations:
schema.graphqls
type Query {
todos: [Todo!]!
}
input NewTodo {
text: String!
userId: String!
}
type Mutation {
createTodo(input: NewTodo!): Todo!
}
Queries and Mutations are defined under their respective type. (The 'Query' and 'Mutation' keywords are reserved within GQL). They follow the 'name(paramName: paramType): returnType' format. In the above example, 'todos' takes no parameters. A '!' character also denotes a mandatory field or Type restriction. The input type is almost the same as a regular type definition, but is used as a representation for a new object being supplied to some mutation.
Modifying the example schema (and also reading the gql schema documentation), we might come up with the following schema for our example use case:
schema.graphqls
type HockeyTeam {
id: ID!
name: String!
abbreviation: String!
city: String!
gp: Int
w: Int
. . .
. . .
ca: Int
cfp: Float
cap: Float
}
type Query {
teams: [HockeyTeam!]!
team(id: String!): HockeyTeam!
}
input NewTeam {
city: String!
name: String!
abbreviation: String!
}
type Mutation {
createTeam(input: NewTeam!): HockeyTeam!
deleteTeam(id: String!): String!
}
We can define two types of queries: One for a general query of all teams, and another for an individual team assuming we supply its ID as an argument. Both queries must return the HockeyTeam type, but the general query will return an array of them. Hence the '[]' notation.
Two mutations are also defined. createTeam will take in the NewTeam input type, while deleteTeam takes an ID string.
Queries & Mutations
After we have defined our schema (and regenerated using the gqlgen tool), we can start to implement our queries and mutations. The implmentations live in graph/schema.resolvers.go. If we open this file we will see a function for each of the queries and mutations we defined. All of the custom types we defined live in the model sub-module within graph/. We can see that the Teams query resolver expects us to return a slice of '*model.HockeyTeam'. The GQL library will deal with the rest as long as we can provide this.
schema.resolvers.go
func (r *queryResolver) Teams(ctx context.Context) ([]*model.HockeyTeam, error) {
panic(fmt.Errorf("not implemented: Teams - teams"))
}
Now that we know the format needed to return the data to the GQL library, we need to first gather it. While we could write a database query or generate the data within this function, it would be helpful to have some form of main memory storage of our HockeyTeams. The Resolver type is defined in graph/resolver.go and will serve as this dependency injection. We can expand the struct definition to maintain a running list of our HockeyTeams like so:
resolver.go
type Resolver struct {
Teams []*model.HockeyTeam
}
Then the resolver function can be implemented as:
schema.resolvers.go
func (r *queryResolver) Teams(ctx context.Context) ([]*model.HockeyTeam, error) {
return r.Resolver.Teams, nil
}
Of course now we will implement some more logic and DB access functions within these resolvers, but hopefully the basics of the Schema and Resolver type are clear.
VSAM & Recordio
To store our Hockey Team data, we will use a VSAM cluster. We can then use the go-recordio module to interact with it from Go.
We begin by creating our VSAM cluster. Provided within the tutorial repository are some scripts that can assist with the creation of a VSAM cluster taken from Mike Fulton's write-up on VSAM datasets. They can be found in vsam/scripts. First we run crtvsamrepro to create a file we can initialize a dataset from. Then we can use crtvsam to actually create the dataset. This program takes a few arguments to specify the name of the cluster, and the key name/sizes/offset. The create_dataset script shows how to use this program to create the dataset for this tutorial. We have an indexed key for our ID field, and 256 bytes of additional data for each record.
Once the dataset has been created, we can populate it with data. A generation tool can be found in data/. It provides a public function that can randomly generate a given number of HockeyTeams along with their stats. A vsam_cli.go tool is also provided to interact with the dataset from the USS environment. It can print the current dataset, add teams and remove teams.
The final step is to pull from the VSAM dataset for use in our GQL resolver functions. We can set the initial state of our Resolver struct by modifying server.go as follows:
srv := handler.NewDefaultServer(graph.NewExecutableSchema(graph.Config{Resolvers: &graph.Resolver{}}))
The above line can be changed to be:
resolver := &graph.Resolver{
Teams: my_teams_slice,
}
srv := handler.NewDefaultServer(graph.NewExecutableSchema(graph.Config{Resolvers: resolver}))
Where 'my_teams_slice' is a slice of *model.HockeyTeam like the one required in our resolver functions. If we use the recordio module to gather the teams from our dataset we can initialize our resolver to contain the complete list. Then any time we call the createTeam mutation we will simultaneously update our resolvers Teams slice along with the VSAM dataset via recordio functions.
For more information about how to access VSAM datasets from Go with the recordio module, here is a tutorial detailing the process.
Graph Query Language
Now we are ready to test our GQL endpoint. When we run the server, we notice the following message: connect to http://localhost:8080/ for GraphQL playground. The GraphQL playground is a great testing tool provided to us right out of the box. Visiting this address will provide us a UI that can explore our API schema and execute queries/mutations. This is a great tool to utilize during development.
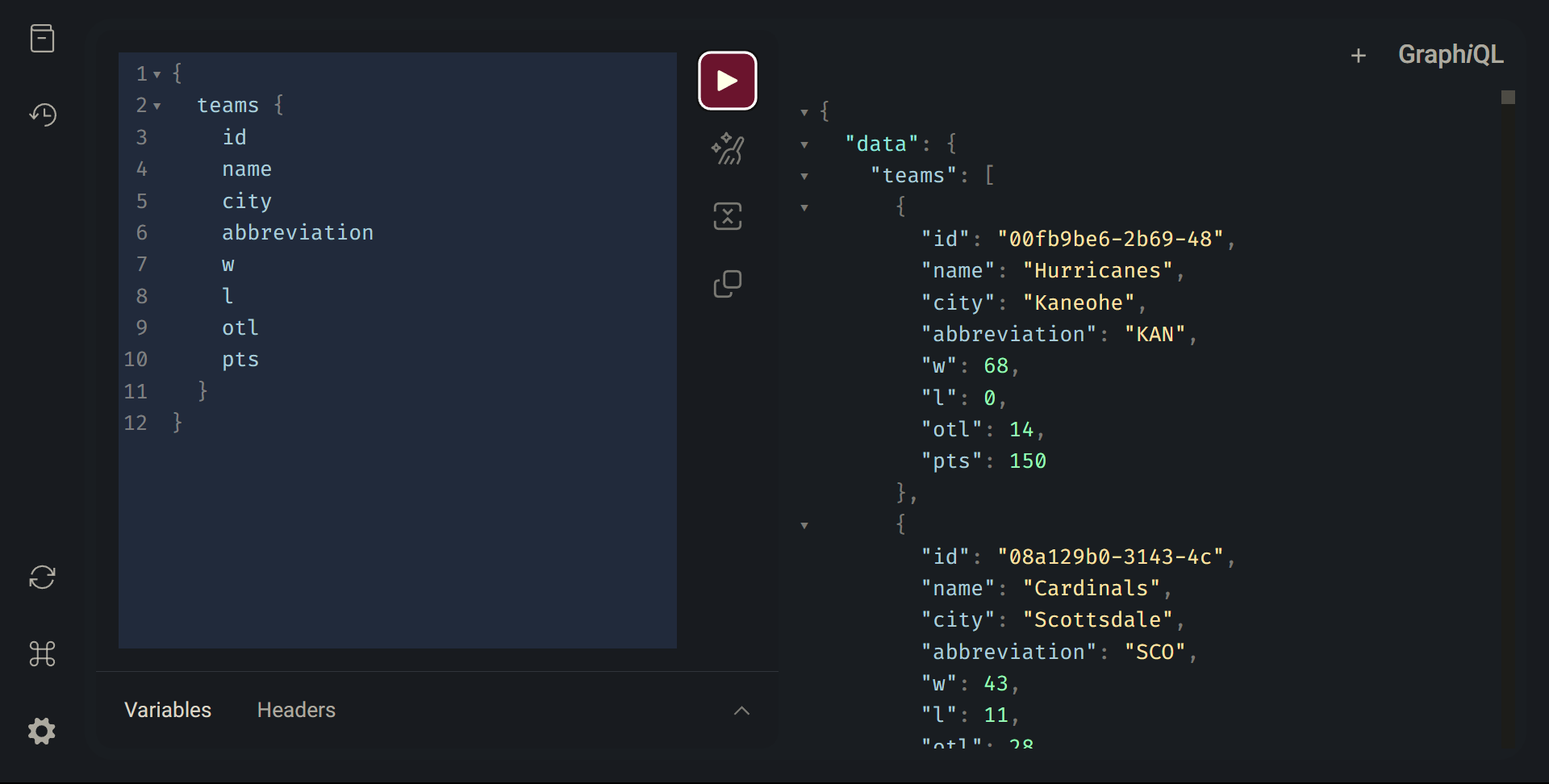
Now lets write the query that solves our use case. It will look like this:
{
teams {
name
city
abbreviation
w
l
otl
pts
}
}
This query contains only the fields we would like to use on our leaderboard. We could also optionally request the id field for future queries involving just one single team. If we execute this in the playground, we should see the requested fields for each of the teams in our database like so:
Now lets try creating a new team. An example mutation might look like this:
mutation {
createTeam(input: {name: "Test Team", city: "Test City", abbreviation: "TST"}) {
id
}
}
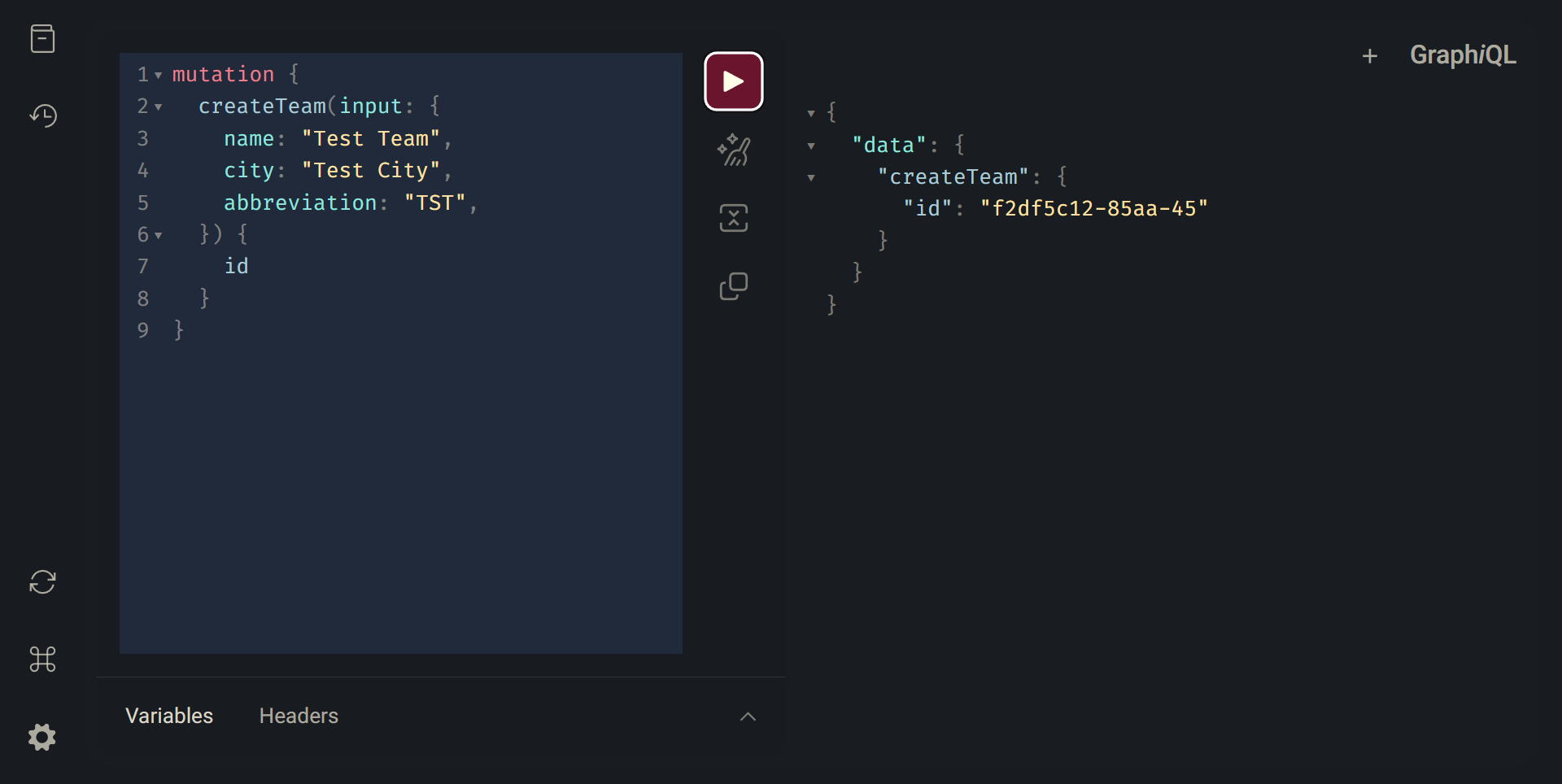
Here we can see that we have provided a NewTeam type in the input field of this mutation. We also request the id of our newly created team be returned so that we can use it for any future requests.
Now that our API is working properly, we want to execute these requests from a JavaScript client to display in a browser. We can use the fetch API built in to JavaScript to write GQL requests to our server and then display them in an html file. The test/ directory in the tutorial repository contains an example that implements this functionality. The fetch request for our general query looks like this:
let data = JSON.stringify({
query: `{
teams {
id
name
city
abbreviation
w
l
otl
pts
}
}`,
});
let opts = {
method: "POST",
. . .
body: data,
}
fetch(GQLURL, opts)
.then((r) => r.json()
.then((data) => {
console.log(data.data.teams);
}))
.catch((e) => console.error(e));
We provide our GQL query as a JSON object in the body of our request to the GQL endpoint. Because we will almost always be supplying a body, we can assume that we will stick to only POST requests for GQL. (GET requests are also supported).
The rest of the above JavaScript code functions like any other HTTP post request. We receive a data object back from the server that contains our teams array. From there we can use this data like any other JavaScript object. We will use this array to populate a table on our example front-end application. See the test/ directory to see the rest of this implementation.

Test Results
In our example application, we implement an interface for both a REST and GQL request to our server. We record the response times and the amount of data being transferred for each request to compare the two different API's. Below are the results over multiple rounds of testing.
| Size |
REST Bytes Transferred |
REST Avg. Response Time |
GQL Bytes Transferred |
GQL Avg. Response Time |
| 10 Teams |
4,153 |
0.1425s |
1,163 |
0.1999s |
| 50 Teams |
20,672 |
0.1284s |
5,751 |
0.2168s |
| 100 Teams |
41,417 |
0.1283s |
11,512 |
0.2145s |
As we would expect we see that our GQL consistently transfers roughly 1/4 of the data compared to the REST API for this scenario. The response times for our GQL is slightly slower on average compared to our REST API, but not in any meaningful way for this example.
Conclusion
With this demo, we can clearly see an example case where a GQL API is superior to a traditional REST API. The flexibility we gain in letting the clients define their own queries allows them to cut down on excess information reducing the total data transferred overall. The ecosystem surrounding GQL is very rich, and provides excellent tools that allow clients to explore complex datasets (See the default playground tool that comes packaged with gqlgen).
This doesn't mean that GQL is be-all and end-all for API development, but its a great tool to have available during the design phase of your application. For datasets that are relatively simple, or requests that serve as a communication method, we may choose to use other API designs like REST or RPC that provide better performance and might be more familiar to our clients.