Introduction
One key feature go Go is a large standard library, supplemented by various extended libraries (available for automatic download), such as x/sys/unix. One important part of those libraries is extensive support for a wide variety of crypto graphic algorithms. These can be found in the standard library directory “crypto” or in the extended library x/crypto. These cryptographic algorithms are crucial for almost any modern application, to secure data and/or communications. Because they are used so frequently, performance considerations are critical for these algorithms. With that in mind, the Go on z/OS team has put considerable effort into optimizing these algorithms. To date, Go on z/OS has accelerated the following cryptographic algorithms: sha1, sha2, sha3, poly1305/chacha20, aes stream cypher (cbc, ctr and gcm), elliptic-curve (ecdsa and ecdh) and md5.
Acceleration Methods
Various techniques are used in accelerating these algorithms
Vector code
An example of acceleration with vector code can be found in the chacha20/poly1305 implementation for s390x. chacha20/poly1305 is a very popular algorithm for fast encrypted streaming with message authentication. Looking in the crypto/chacha20 directory one finds chacha_s390x.s, which contains about 225 lines of assembly code to process chacha20 blocks using vector operations to process 16 bytes at at time. Similarly in the directory crypto/internal/poly1305 one will find sum_s390x.s, which, in about 500 lines of assembly, processes the poly1305 authentication protocol using vector operations. The following is a small snippet of this code, showing part of the assembler macro for multiplication.
141 #define MULTIPLY(f0, f1, f2, f3, f4, g0, g1, g2, g3, g4, g51, g52, g53, g54, h0, h1, h2, h3, h4) \
142 VMLOF f0, g0, h0 \
143 VMLOF f0, g3, h3 \
144 VMLOF f0, g1, h1 \
145 VMLOF f0, g4, h4 \
146 VMLOF f0, g2, h2 \
147 VMLOF f1, g54, T_0 \
148 VMLOF f1, g2, T_3 \
149 VMLOF f1, g0, T_1 \
150 VMLOF f1, g3, T_4 \
151 VMLOF f1, g1, T_2 \
152 VMALOF f2, g53, h0, h0 \
153 VMALOF f2, g1, h3, h3 \
154 VMALOF f2, g54, h1, h1 \
155 VMALOF f2, g2, h4, h4 \
156 VMALOF f2, g0, h2, h2 \
157 VMALOF f3, g52, T_0, T_0 \
158 VMALOF f3, g0, T_3, T_3 \
159 VMALOF f3, g53, T_1, T_1 \
160 VMALOF f3, g1, T_4, T_4 \
161 VMALOF f3, g54, T_2, T_2 \
162 VMALOF f4, g51, h0, h0 \
163 VMALOF f4, g54, h3, h3 \
164 VMALOF f4, g52, h1, h1 \
165 VMALOF f4, g0, h4, h4 \
166 VMALOF f4, g53, h2, h2 \
167 VAG T_0, h0, h0 \
168 VAG T_3, h3, h3 \
169 VAG T_1, h1, h1 \
170 VAG T_4, h4, h4 \
171 VAG T_2, h2, h2
This macro is a key component of the "schoolbook multiplication" portion of the poly1305 algorithm. In order to compute the authentication code, it is necessary to perform a repeated sequence of multiplications modulo a prime, so the speed of the algorithm essentially comes down to how quickly large multiplications can be performed.
CPACF
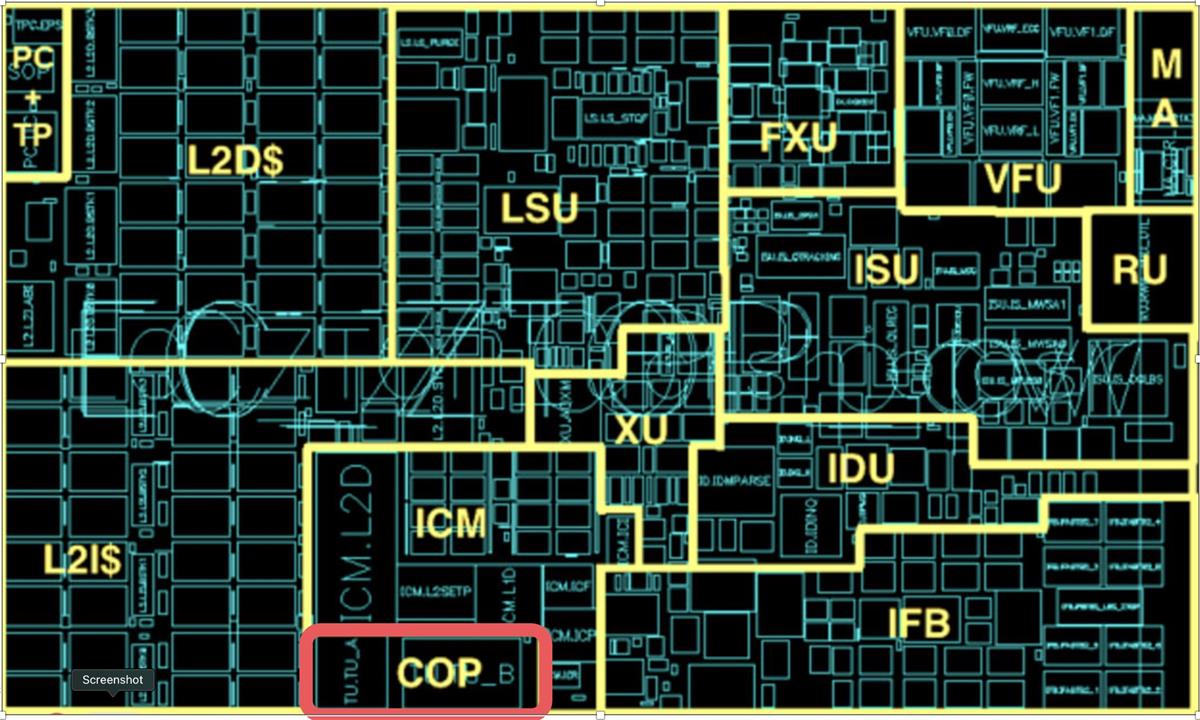
CPACF stands for “CP Assist for Cryptographic Functions,” and it consists of an cryptographic acceleration processor which is a part of every processor core in a z system. For example, here is a graphic of the z15 processor showing the area devoted to the co-processor (COP).
CPACF provides highly tuned instructions that cover a wide range of cryptographic operations. With CPACF we have been able to accelerate sha1, sha2, sha3, aes stream cypher (cbc, ctr and gcm), elliptic-curve (ecdsa and ecdh) and md5. Typically, the way that CPACF is employed is. through the use of specialized instructions, which are outlined in the Principles of Operation. As an example of how this works, consider the implementation of Elliptic Curve Digital Signature Authentication (ECDSA) in Go on z. This is implemented with the KDSA instruction:
This single instruction covers creating a signature and verifying it, over three signature sizes: 256, 384, and 512 bits. It's a complicated instruction, with fifteen dense pages devoted to it in the Principles of Operation. To use the instruction one has to first enquire if the instruction is available (it requires z15 or later), and then set up various buffers and parameters. However, using the instruction itself is easy in Go, as Go has it's own assembler. Here is the totality of the code in ecdsa_s390x.s, which calls the instruction:
// Copyright 2020 The Go Authors. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.
#include "textflag.h"
// func kdsa(fc uint64, params *[4096]byte) (errn uint64)
TEXT ·kdsa(SB), NOSPLIT|NOFRAME, $0-24
MOVD fc+0(FP), R0 // function code
MOVD params+8(FP), R1 // address parameter block
loop:
WORD $0xB93A0008 // compute digital signature authentication
BVS loop // branch back if interrupted
BGT retry // signing unsuccessful, but retry with new CSPRN
BLT error // condition code of 1 indicates a failure
success:
MOVD $0, errn+16(FP) // return 0 - sign/verify was successful
RET
error:
MOVD $1, errn+16(FP) // return 1 - sign/verify failed
RET
retry:
MOVD $2, errn+16(FP) // return 2 - sign/verify was unsuccessful -- if sign, retry with new RN
RET
Note that the Go assembler lacks a nemonic for KDSA, so a bytecode version of it is used (WORD $0xB93A0008).
Performance
So how much does all of this acceleration effort help performance? You can check it out for yourself using Go's built-in benchmarking facilities. If you have Go on z/OS installed on your system, you can change directory to any crypto algorithm and run the available benchmarks using the command For example,
go test -bench=Bench
For example, if you 'cd' to the directory src/crypto/ecdsa, and type "go test -bench=Bench" you might see something like this