At this point, you may be wondering if only there was a way to write and execute batch jobs without having to deal with JCL. Well, there is! With the release of IBM z/OS Core Collection of Ansible modules v1.2.0-beta.1, you will now be able to execute MVS commands using the zos_mvs_raw module. Let's see how this can be done by executing a simple batch job. But before we proceed, be sure to check out how Ansible works if you are not familiar with Ansible.
For demonstration purposes, let's assume that we have a sequential data set that contains a list of names in one column and the corresponding age in the second column. We would like to sort the data set based on age in descending order.
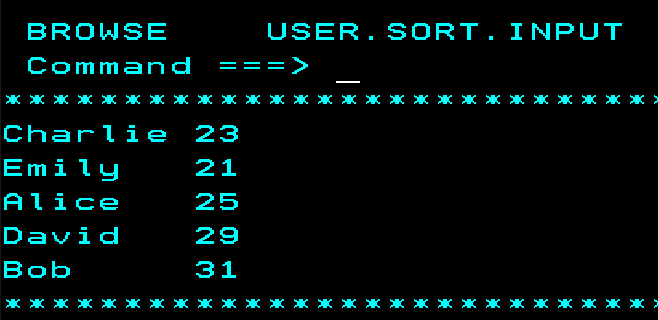 Normally, we would write a JCL to execute DFSORT on that particular data set. Something like this perhaps:
Normally, we would write a JCL to execute DFSORT on that particular data set. Something like this perhaps:
//USRT001 JOB 'SORTDS',
// NOTIFY=USRT001,
// USER=USRT001,
// MSGCLASS=E,
// MSGLEVEL=(1,1),
// CLASS=A
//*
//SORT EXEC PGM=SORT
//SYSOUT DD SYSOUT=*
//SORTIN DD DSN=USER.SORT.INPUT,DISP=SHR
//SORTOUT DD DSN=USER.SORT.INPUT,DISP=OLD
//SYSIN DD *
SORT FIELDS=(9,2,BI,D)
/*
Afterwards, we would submit the job. The same program can be created and executed using Ansible by writing a simple task with the zos_mvs_raw module:
- name: Sort the data set based on age in descending order
zos_mvs_raw:
program_name: sort
dds:
- dd_output:
dd_name: sysout
return_content:
type: text
- dd_data_set:
dd_name: sortin
data_set_name: USER.SORT.INPUT
disposition: shr
- dd_data_set:
dd_name: sortout
data_set_name: USER.SORT.INPUT
disposition: old
- dd_input:
dd_name: sysin
content: " SORT FIELDS=(9,2,BI,D)"
And that is it! We can see that DFSORT was executed and the data set has been sorted.
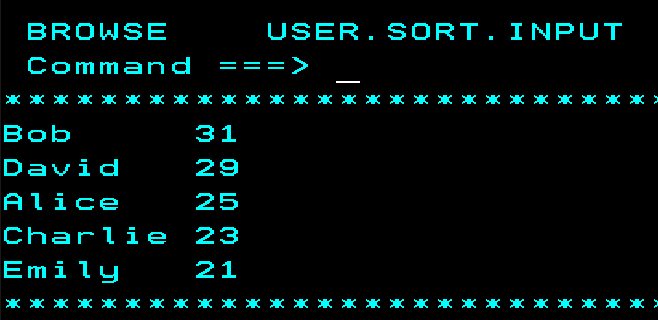 The
The zos_mvs_raw module returns a JSON response containing the return code, any backups made, the output stored in output DD (if it was specified) and the module invocation parameters. The response for this particular task is given below. Note that the response has been abbreviated for the sake of clarity.
changed: [ec33013a.vmec.svl.ibm.com] => {
"backups": [],
"changed": true,
"dd_names": [
{
"byte_count": 37,
"content": [
"\f SORT FIELDS=(9,2,BI,D)",
""
],
"dd_name": "sysout",
"name": "OMVSADM.P3886510.T0865049.C0000000",
"record_count": 2
}
],
"invocation": {
"module_args": {
"auth": false,
"dds": [
{
"...": "...",
"dd_output": {
"dd_name": "sysout",
"return_content": {
"response_encoding": "iso8859-1",
"src_encoding": "ibm-1047",
"type": "text"
}
},
},
{
"dd_data_set": {
"backup": false,
"block_size": null,
"data_set_name": "USER.SORT.INPUT",
"....": "...",
}
},
{
"dd_data_set": {
"...": "...",
"data_set_name": "USER.SORT.INPUT",
"...." : "....",
{
"dd_input": {
"content": " SORT FIELDS=(9,2,BI,D)",
"dd_name": "sysin",
"return_content": null
},
}
],
"program_name": "sort"
}
},
"ret_code": {
"code": 0
}
So far so good but the capability of zos_mvs_raw far exceeds what is demonstrated above. For instance, what if we wanted to sort the data set and store the output to a different, non-existent data set? Well, if we were writing JCL, we could change our SORTOUT DD statement to allocate a new data set by indicating its allocation parameters:
//SORTOUT DD DSN=USER.SORT.OUTPUT,DISP=(NEW,CATLG),
DCB=(LRECL=80,RECFM=FB,BLKSIZE=32720),
DSORG=PS,
SPACE=(32000,(30,10)),
VOL=SER=000000
But we're not writing a JCL. Instead, let's see how we can accomplish this through Ansible:
- name: Sort the data set based on age in descending order
zos_mvs_raw:
program_name: sort
dds:
- dd_output:
dd_name: sysout
return_content:
type: text
- dd_data_set:
dd_name: sortin
data_set_name: USER.SORT.INPUT
disposition: shr
- dd_data_set:
dd_name: sortout
data_set_name: USER.SORT.OUTPUT
disposition: new
disposition_normal: catlg
type: seq
record_length: 80
record_format: fb
block_size: 32720
space_type: k
space_primary: 30
space_secondary: 10
volumes: '000000'
- dd_input:
dd_name: sysin
content: " SORT FIELDS=(9,2,BI,D)"
Essentially, all we did was change our sortout dd_data_set parameter by adding new data set allocation details. Again, this is only scratching the surface of what zos_mvs_raw is capable of and I encourage you to visit the z/OS core collection documentation page to learn about what other features it provides. The simplicity of YAML combined with the ease of use of the Ansible eco system makes IBM z/OS core collection an exciting alternative to traditional mainframe development practices.
If you'd like to see the complete playbook and other sample playbooks, check out the Ansible z/OS Collection Sample Playbooks repository.
Links