Welcome to the
AirTravel hands-on lab series. You are ready for departure with Silver membership status. This path will give you essential experience with Red Hat OpenShift Environment on IBM LinuxONE Community Cloud.
During this hands-on lab, you will:
- Deploy a Node.js application on OpenShift using a builder image
- Create a secret and make it available as an environment variable
- Deploy a Mongo database from the container image
- Add persistent storage to the database
- Test the Node.js application that uses Mongo database for storing data
Prerequisites:
Lab duration: 30 minutes
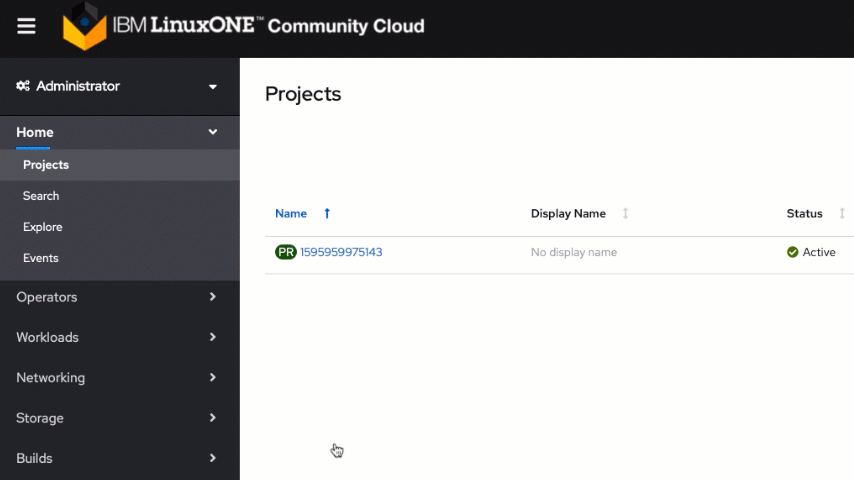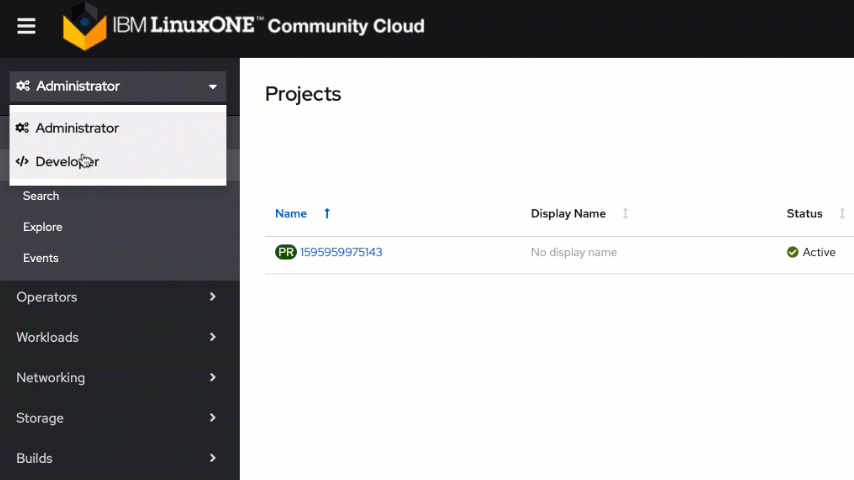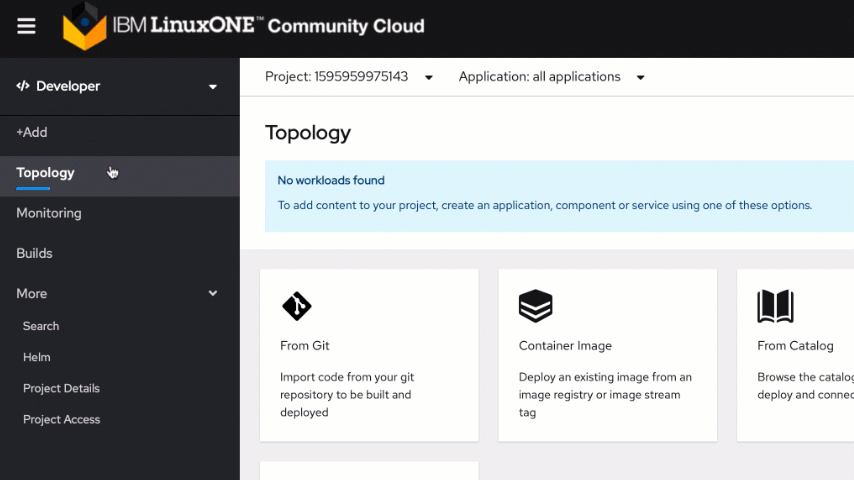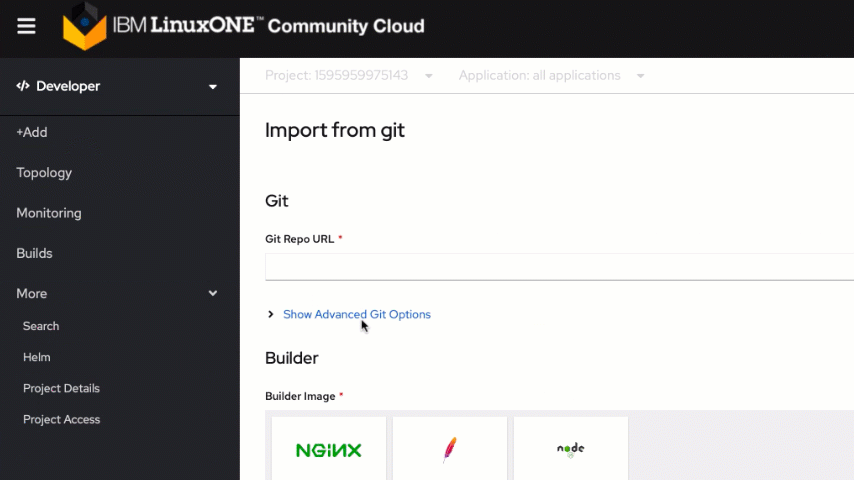
Let's start by logging in to the web console of your provisioned Red Hat OpenShift environment on IBM LinuxONE Community Cloud.
Next, switch to the Developer view and click on the "From Git" tile on the "+Add" tab.
This OpenShift environment has several builder images listed in a catalog, and for this lab, you will use a Node.js image to deploy an application from a Git repository.
You need to specify the following repository location (which has our application code) in the "Git Repo URL" field:
https://github.com/andriivasylchenko/node-app-l1cc-openshift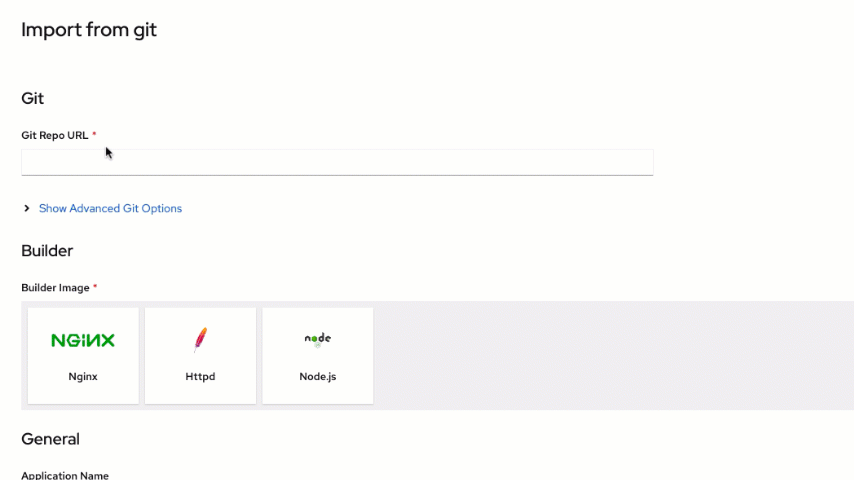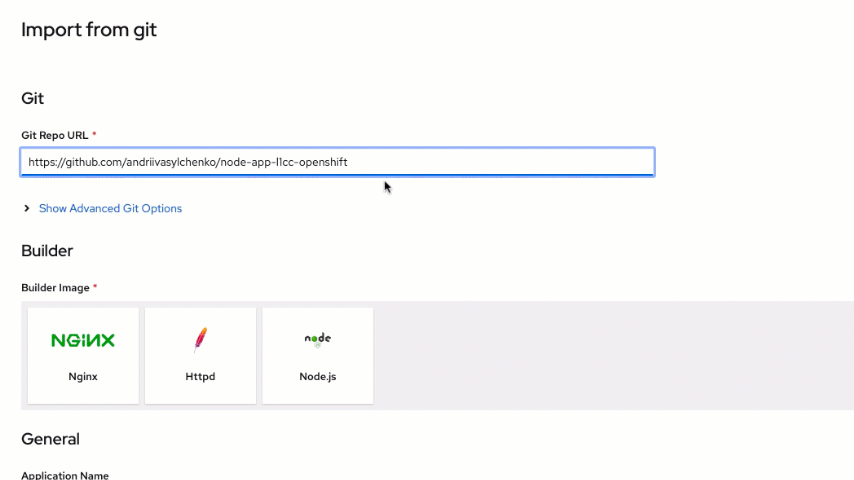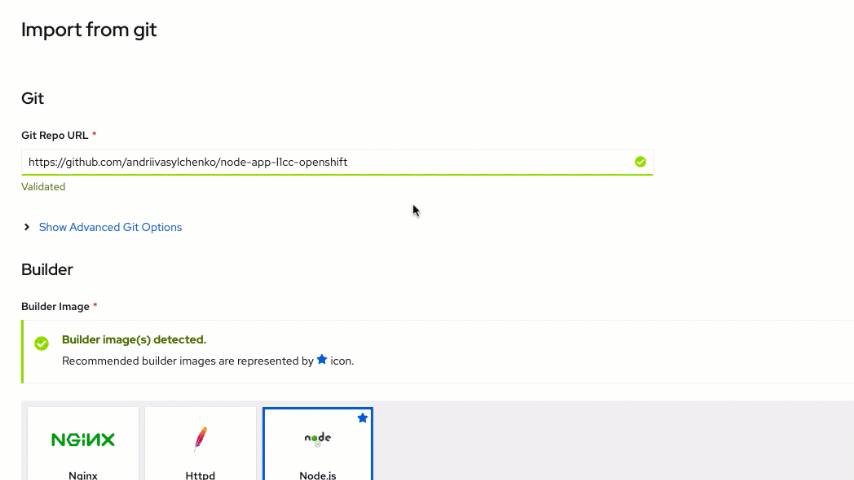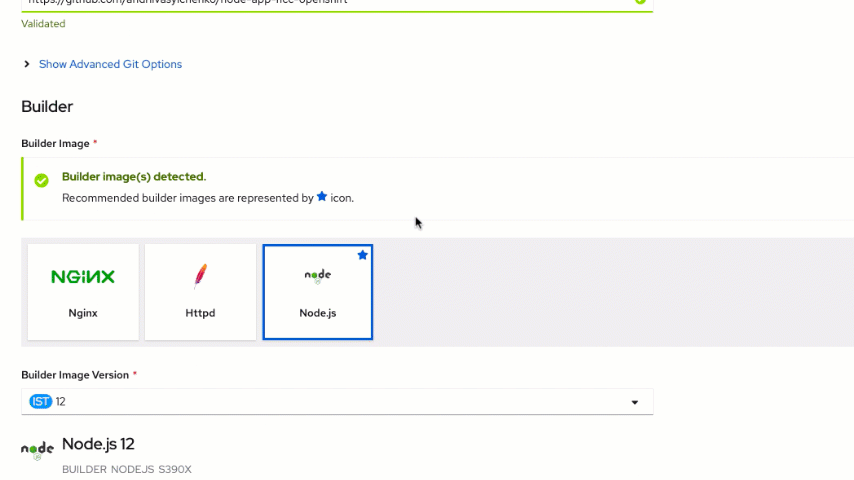
Notice that the Node.js image was selected based on the metadata provided by GitHub.
Your next step is the application and component naming configuration. You should use
air-travel as an application name, which will be a holder for two of your main components - this Node.js application component and the database. In the name field, let's put
node-app.

Most of the other default configuration is good to go, except for two specific settings to our environment.
You will also need to specify the API user key and password that Node.js app uses during runtime. You can technically do it right here in the "Deployment" section with the environment variables fields. However, because those will hold sensitive data, you will use secrets for this purpose later in the lab.
Navigate to the bottom of the page and click on the "Scaling link". Set the "Replicas" value to 0 for now. You will proceed step-by-step with exploring the build and scaling the application later on.

Now, you need to specify how many resources to allocate for the component. This is a mandatory step for OpenShift on IBM LinuxONE Community Cloud because it has a quota allocated for each trial project, like the one you have here. To set resources allocation, click Resource Limit and then, in exposed the section, fill the Memory and CPU limits.
Your project has the following overall quota:
- CPU: 1 core
- Memory: 4 Gb
- Storage: 5 Gb
- Persistent storage claims: 5
CPU is measured in units called millicores, and 1 core equals 1000 millicores, which you can allocate anyhow you want among your pods.
Memory and storage settings use Mi and Gi as abbreviations for megabytes and gigabytes, respectively. A persistent storage claim means the ability to define a storage share that can be mounted to your pods.
The "Request" field represents the minimum amount that is guaranteed for a component, while "Limit" constrains the maximum. Your quota usage for Memory and CPU is calculated based on the limits values you set.
Also, it is important to keep in mind that builds consume resources as well. By default, if the limits are not specified in the build config, the build will use 500 millicores of CPU and 2 Gi of Memory. Those are the default values set for the OpenShift environment on IBM LinuxONE Community Cloud.
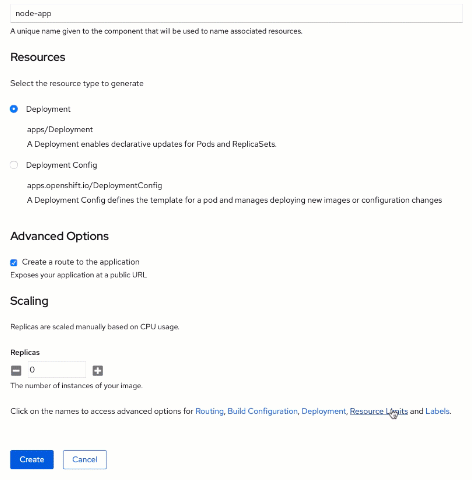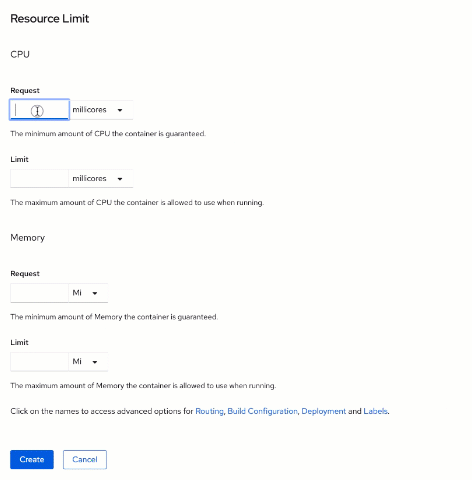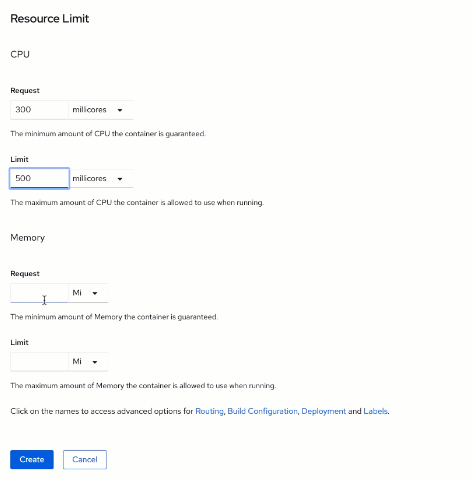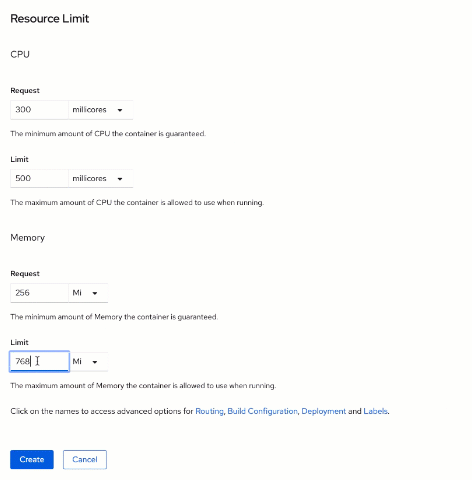
For this lab, set the
CPU request value to
300,
limit to
500; and the
Memory request to
256Mi and
limit to
768Mi.
Proceed by clicking the "Create" button. This will create an application, component, network service, and route and a couple of secrets to connect to the GitHub repository and start the build.
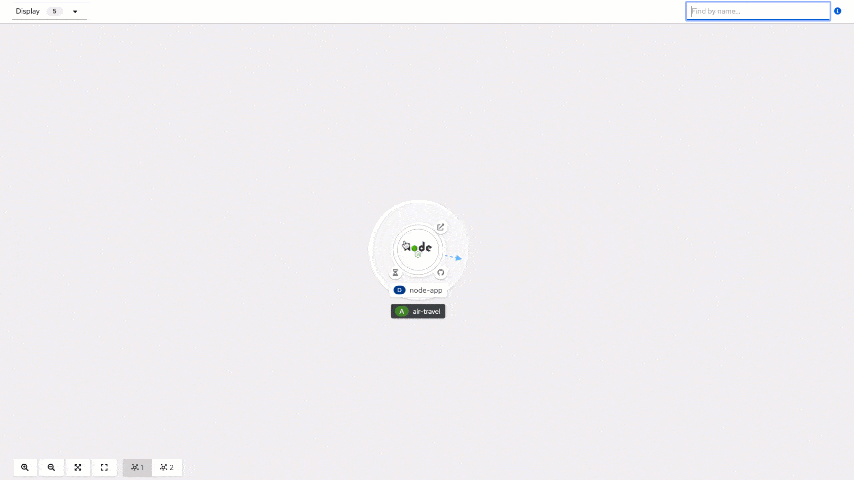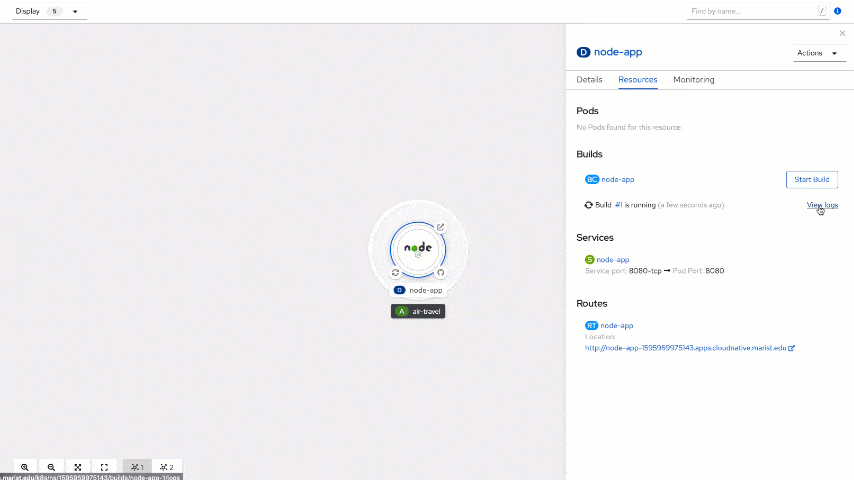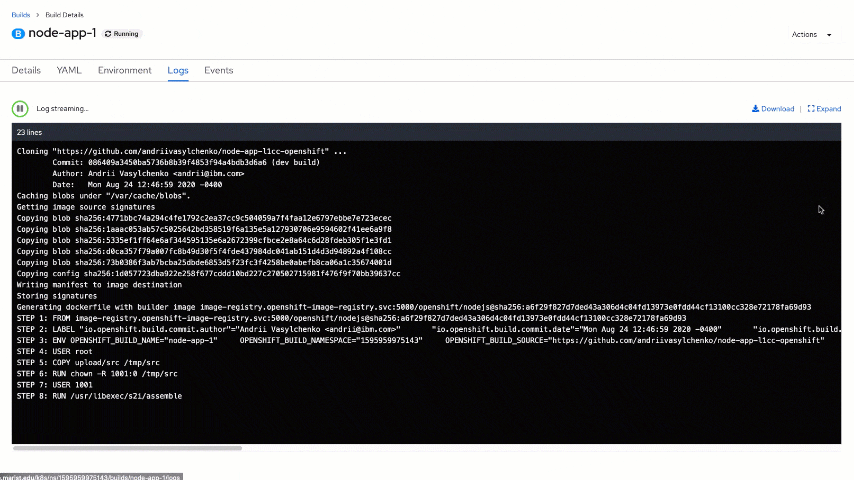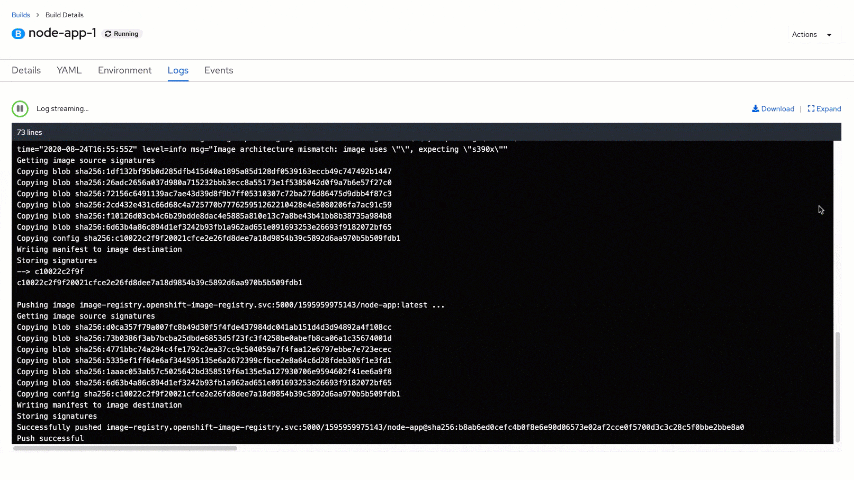
You will land on the "Topology" view. The next step is to click on node-app and examine the build using the "View logs" link on the "Resources" tab. Here, in real-time, you may see what is happening as part of the build steps. You will start with cloning a Node.js application repository, then generating a docker file with a selected builder image. Part of the execution is automated launch of "npm install" that will download and install all node_modules specified in your package.json file (and their dependencies).
Also, take a quick look at the "Events" tab, which lists high-level events related to the build and potential errors.
Once the build is complete, a prepared image is pushed to the internal registry, ready to be consumed.
Before launching a pod, you need to set those environment variables mentioned earlier using a "secret". To do so, switch to the "Administrator" view and click on "Secrets" in the expanded "Workloads" section inside the menu panel.
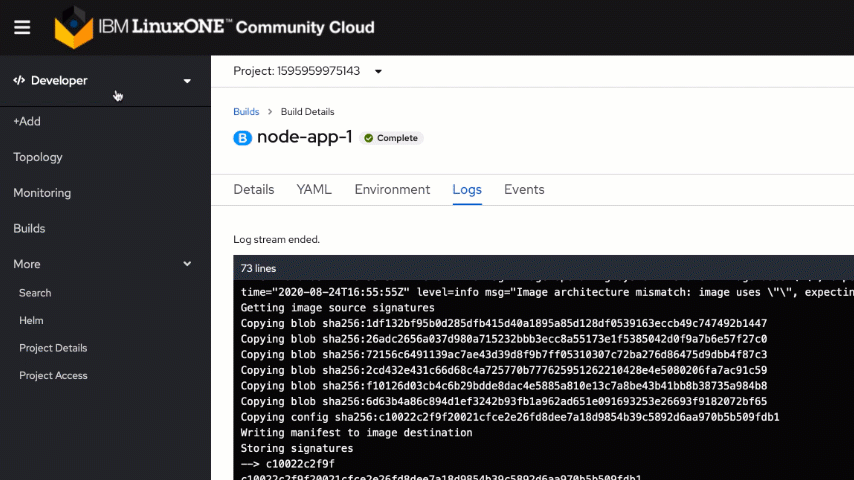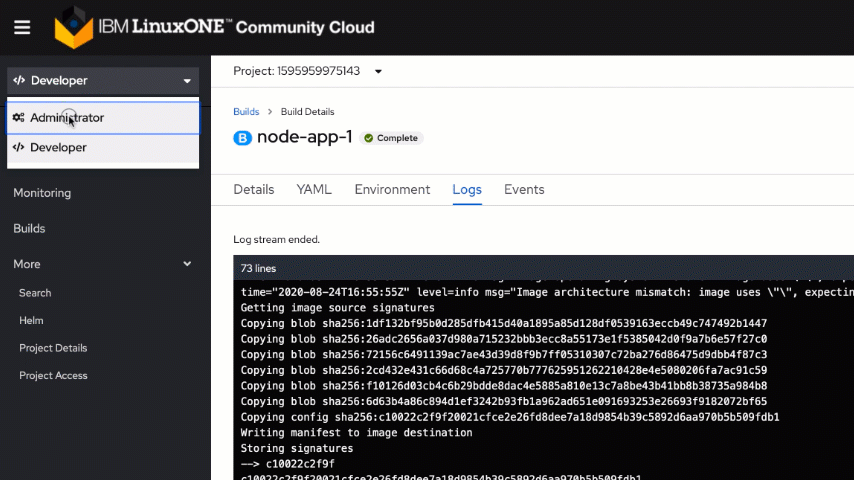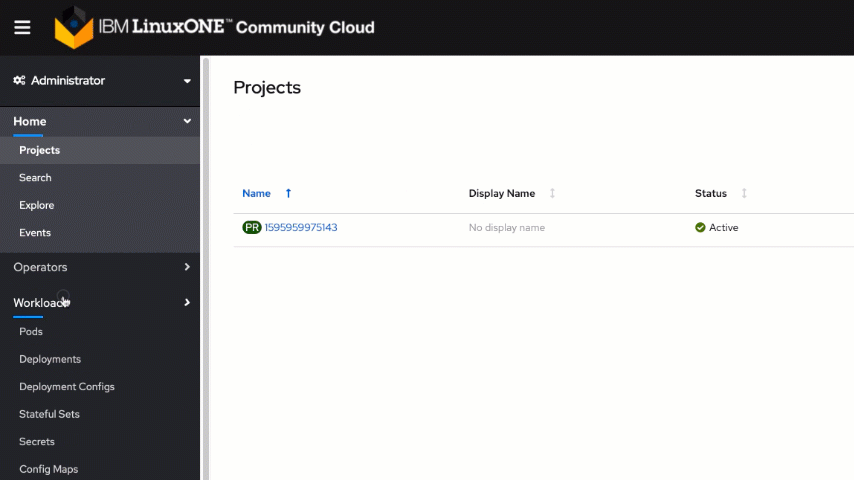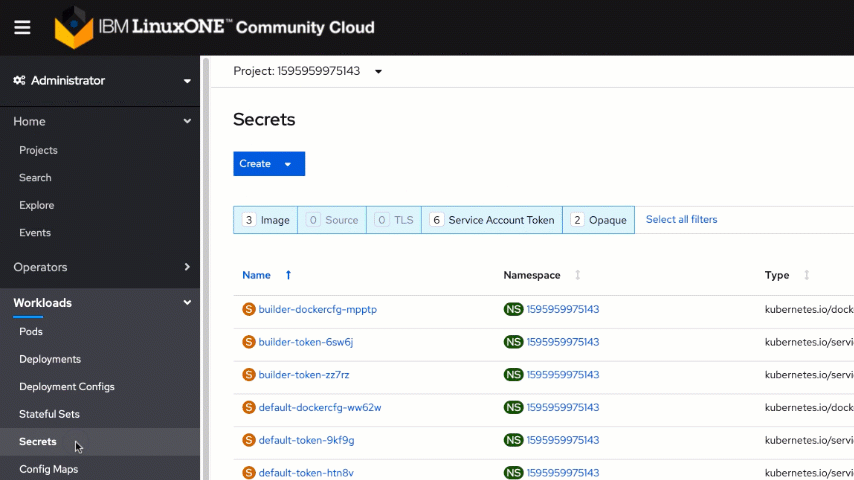
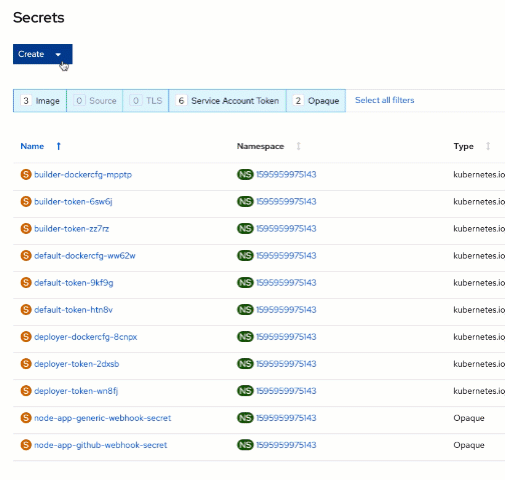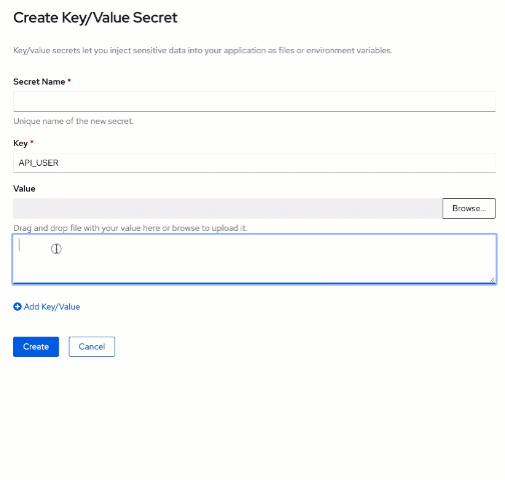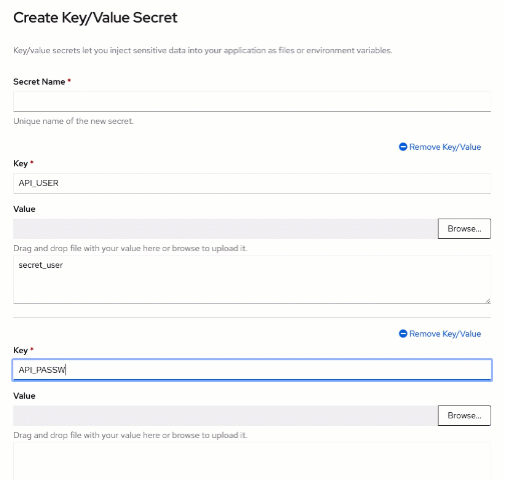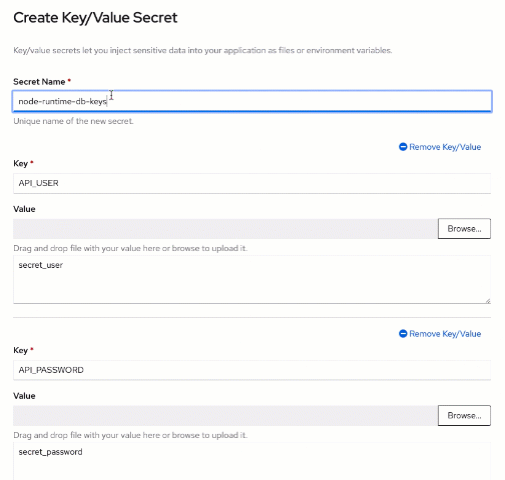
Create a new "Key/Value Secret" using the "Create" button on top and then create the following two entries:
- API_USER : secret_user
- API_PASSWORD : secret_password
In the Key and Value text fields, respectively. Use
node-runtime-db-keys as the "Secret name" and then click "Create".
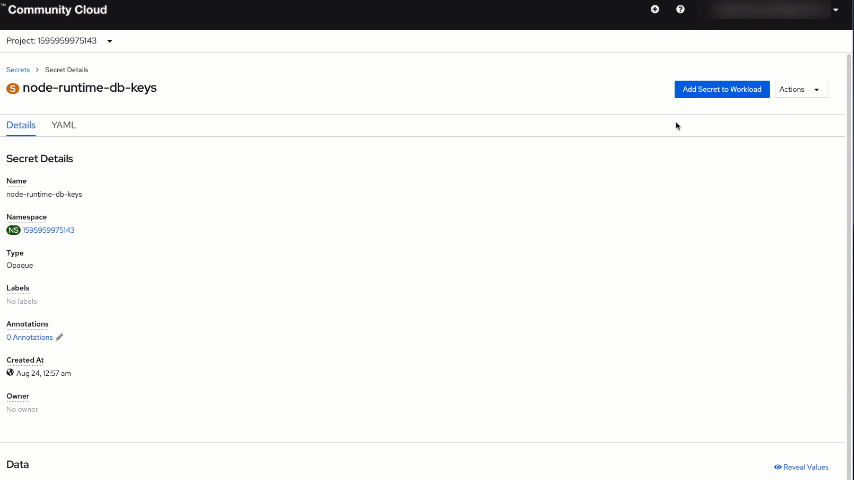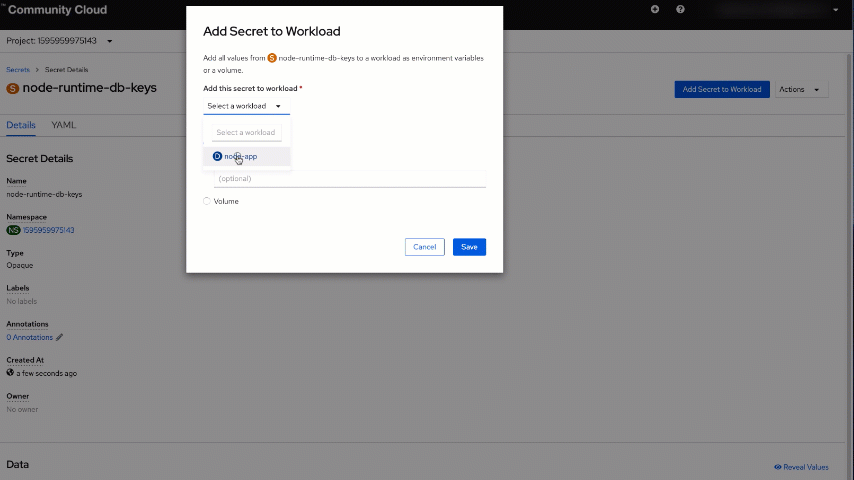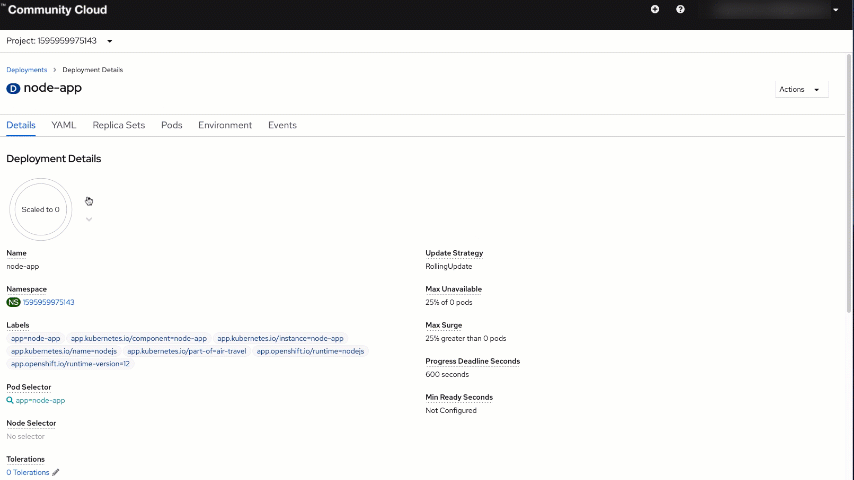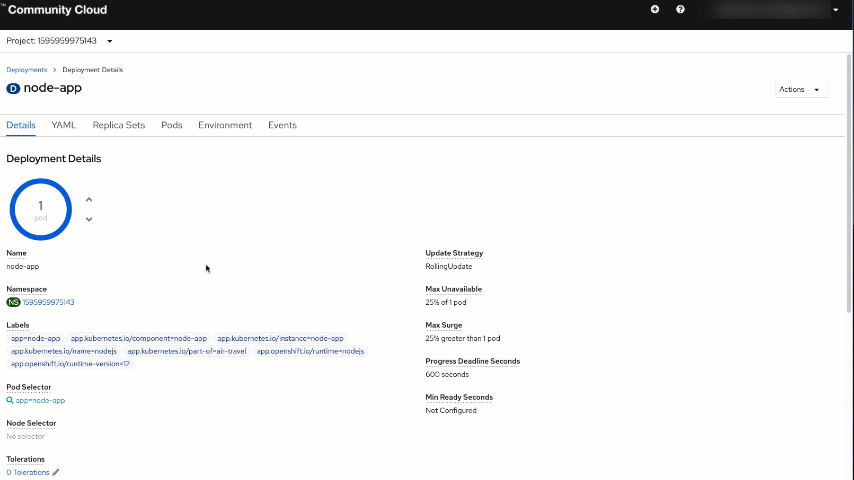
Next, add the new secret keys as environment variables for the Node.js application. To do that, click on the "Add Secret to Workload" button in the top right corner, select "node-app" and save these settings.
You will be taken to your node application deployment view, which is a perfect segue to the next step. Set the "Scaled" value in the circle to 1, which will create the pod using the image from the registry that you previously created.
Switch back to the "Developer" view and look again at your "node-app" resources tab. You should see now a pod running there.
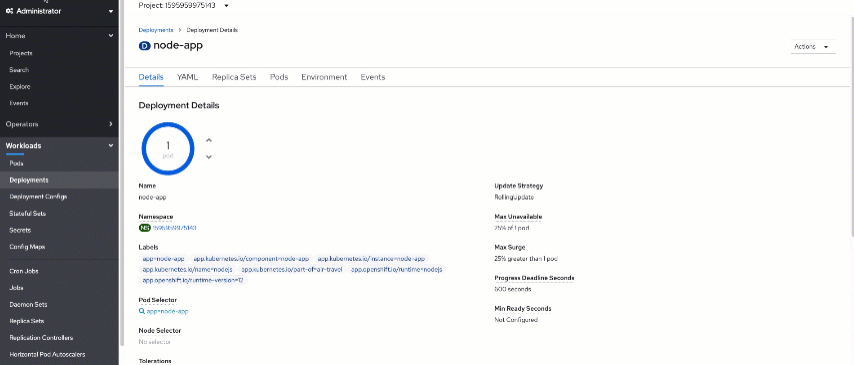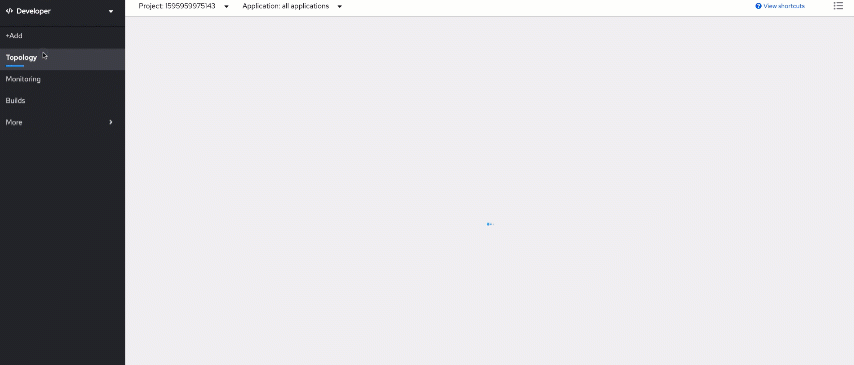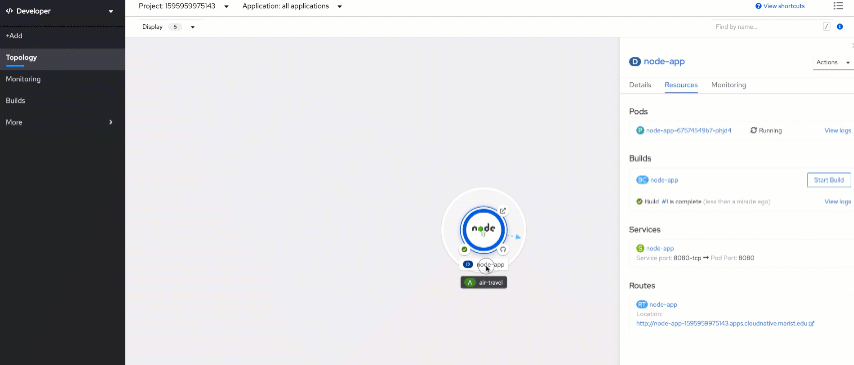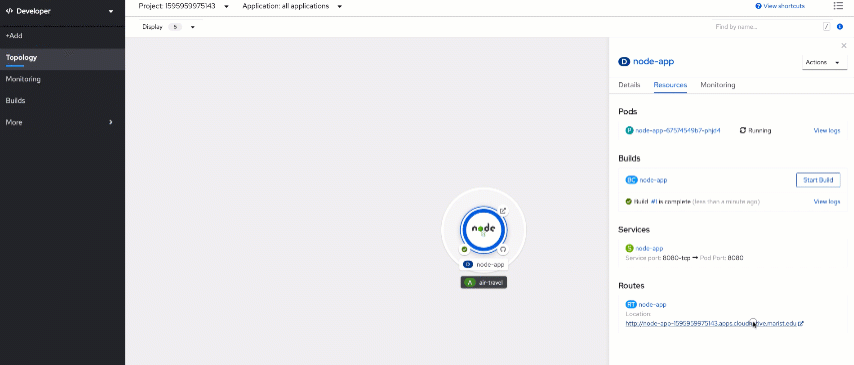
It's now time to take a look at the app itself. Open the URL you see in Routes at the bottom of the tab.
In this lab, you will not need to work with real flight data from Amadeus APIs. Instead, you should open the application settings using the wheel in the top right corner, toggle "Emulate Amadeus API calls", and then click "Ok".
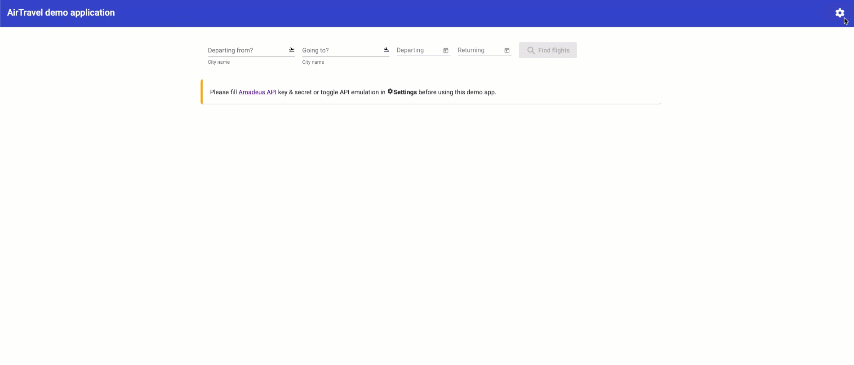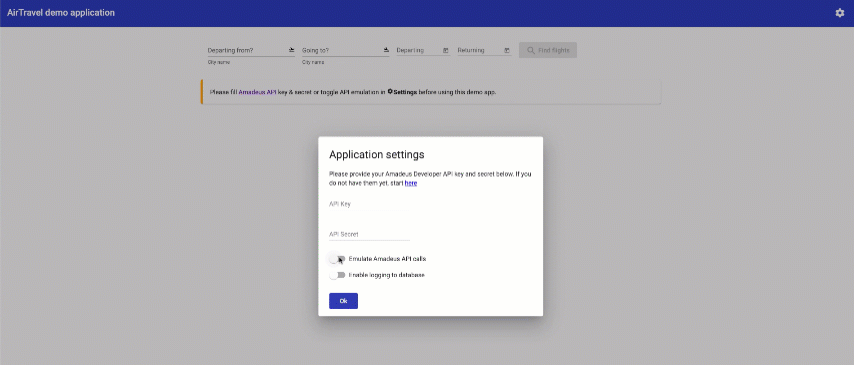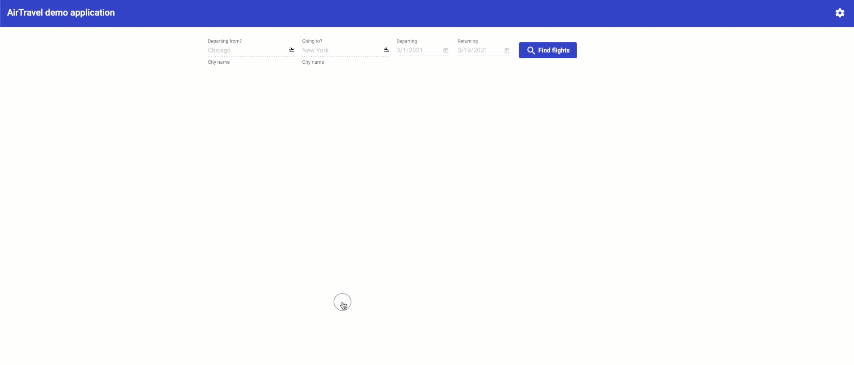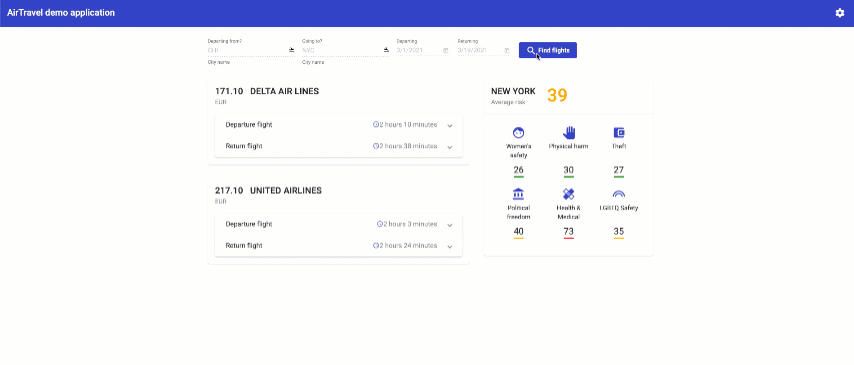
You will get pre-populated query fields ready for searching within mock data. Find your flight!
Results that you are getting consist of emulated output from 3 API calls:
In Gold and Platinum membership labs, you will be operating with real API endpoints, but for Silver membership, you are all set for now.
It's time to deploy the database! You will use it to log each API query performed within the app. Go back to the OpenShift web console. Click on "+Add" and select the "Container Image" tile. Search for s390x/mongo image from the external registry.
Important! Type "
s390x/mongo" instead of "mongo" when searching for a database image
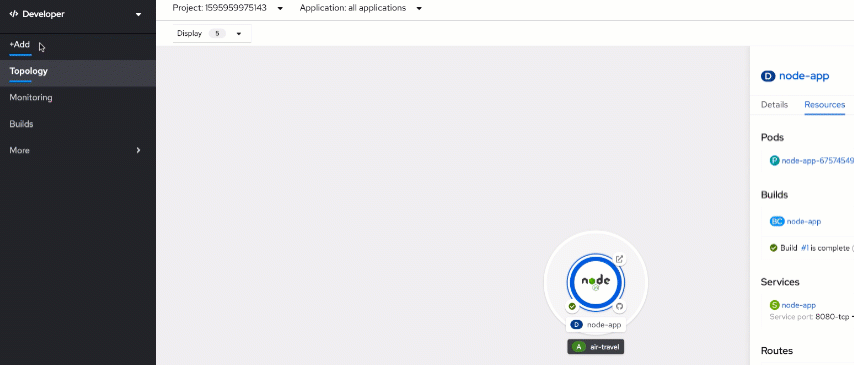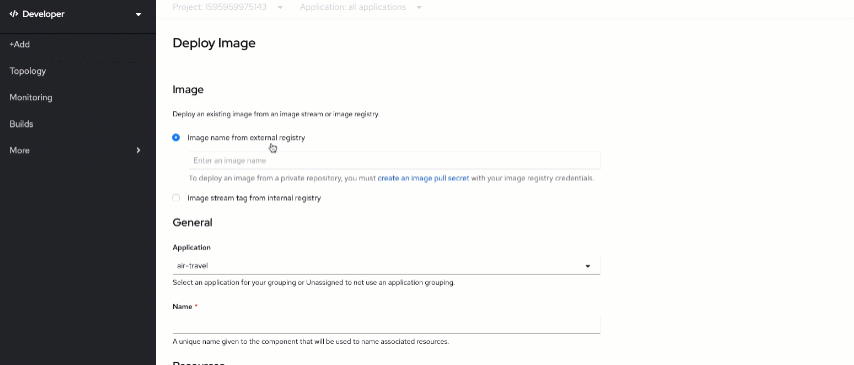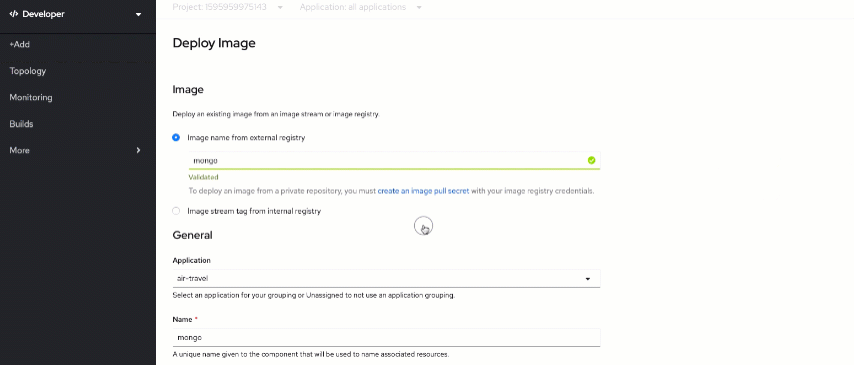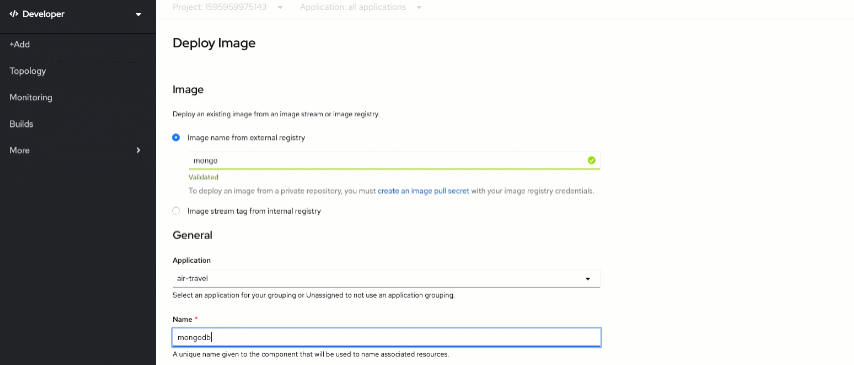
Ensure that "air-travel" is selected as an application and put
mongodb as a component name.
You also need to set the resource limits the same as last time:
- CPU request: 300
- CPU limit: 500
- Memory request: 256 Mi
- Memory limit: 768 Mi
Click "Create" when you are done with the configuration.
Your topology now should have a second component under the "air-travel" application. Take a look at the "mongodb" Resources tab - there should be a pod in a running state once the image is pulled from the external repository and processed.

Go back to the "AirTravel" Node.JS application tab in your browser. Open the settings again and toggle "Enable logging to database". After clicking "Ok", you should see a second button next to settings.
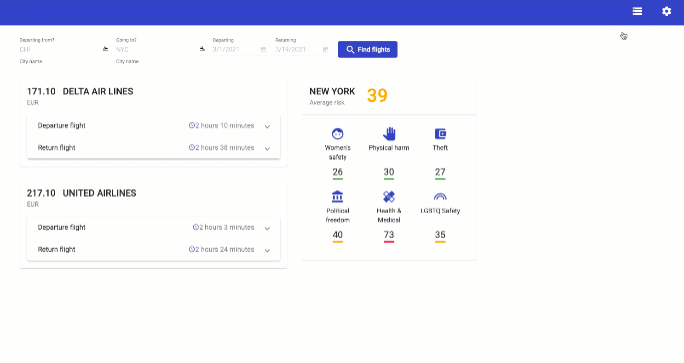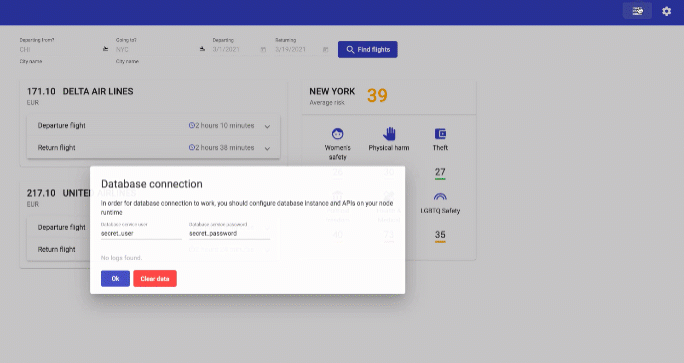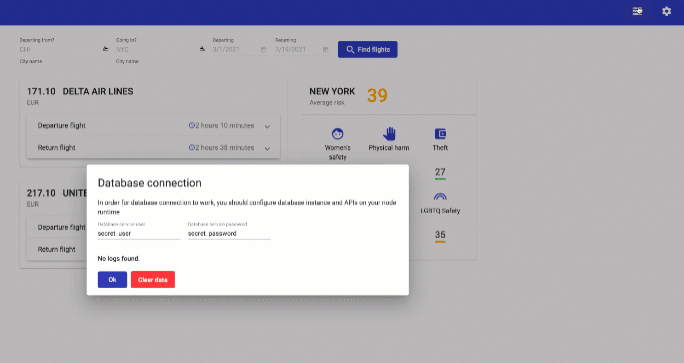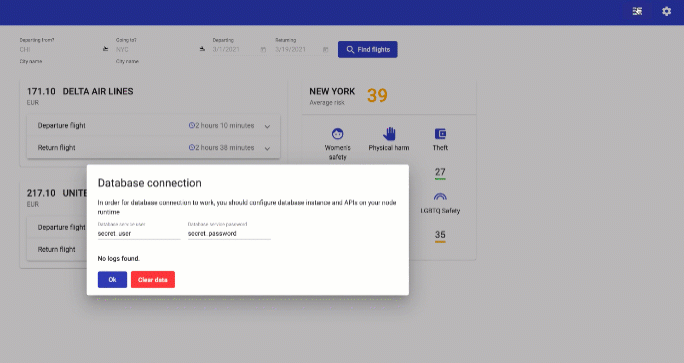
Try performing a flight search and then going back to the database connection window using a new button.
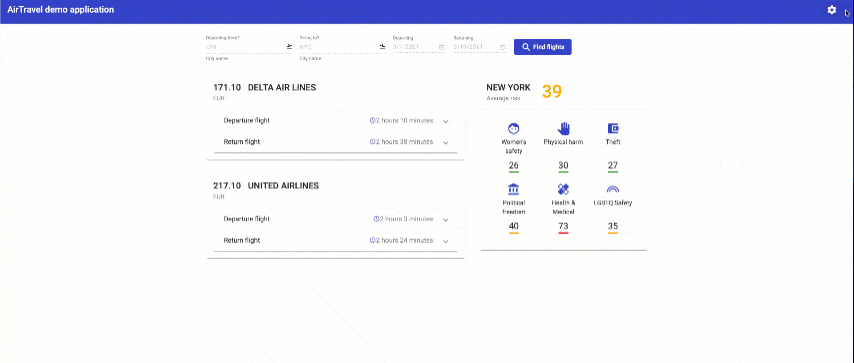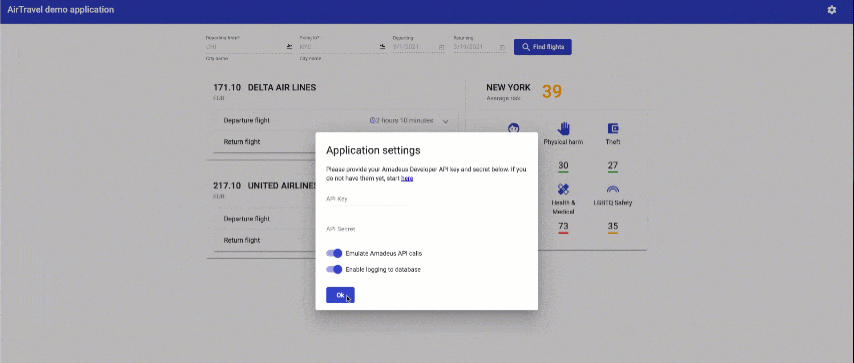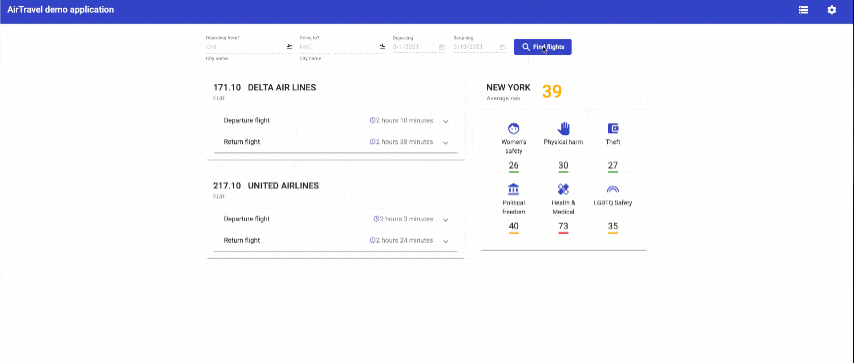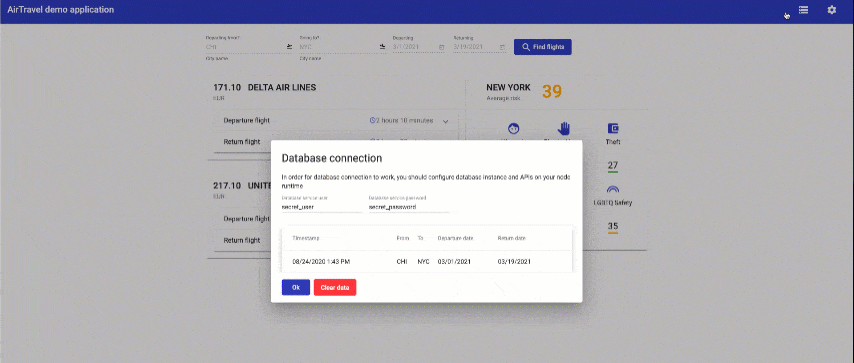
Congratulations! You successfully logged your search query into the Mongo database! Let's clarify how this happened. Node application is connected to the mongo database internally, within air-travel that holds both of the components. Names that were asked to fill are used as a reference to locate and connect to the database. The secret that you created is used to connect from the Angular application to the Node runtime that it is running through APIs using those key/values as a basic authorization. It is done this way to support the Platinum membership lab, where there is a local development flow with a requests proxy to a database pod running inside the OpenShift Container Platform.
The last thing for you to do in the lab is to connect persistent storage to your database. You can start by checking the current behavior. Go back to the OpenShift web console and scale the "mongodb" to 0 and then back to 1 using "Edit counts" inside the "Actions" menu in the top right corner. Now, inside your "AirTravel" application, open "Database connection" window again.

Do you see the issue? Your logged query is gone. To prevent this, you will need to claim persistent storage volume and mount it to the database.
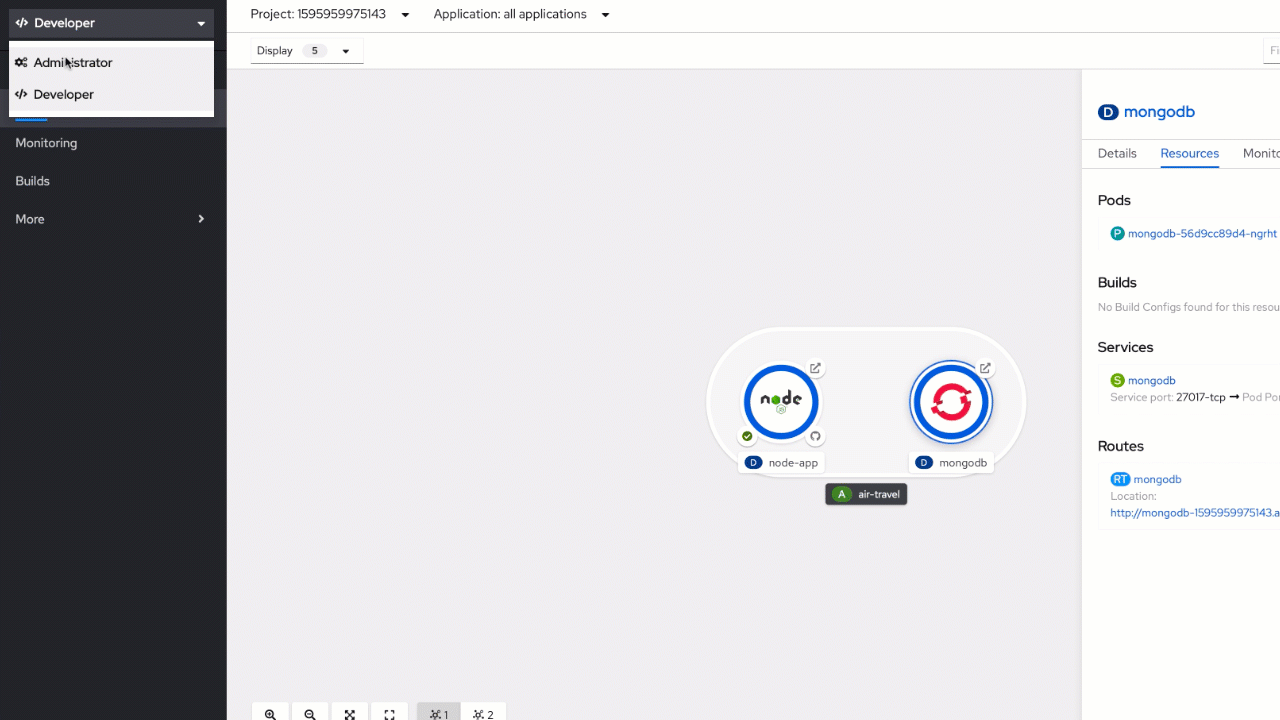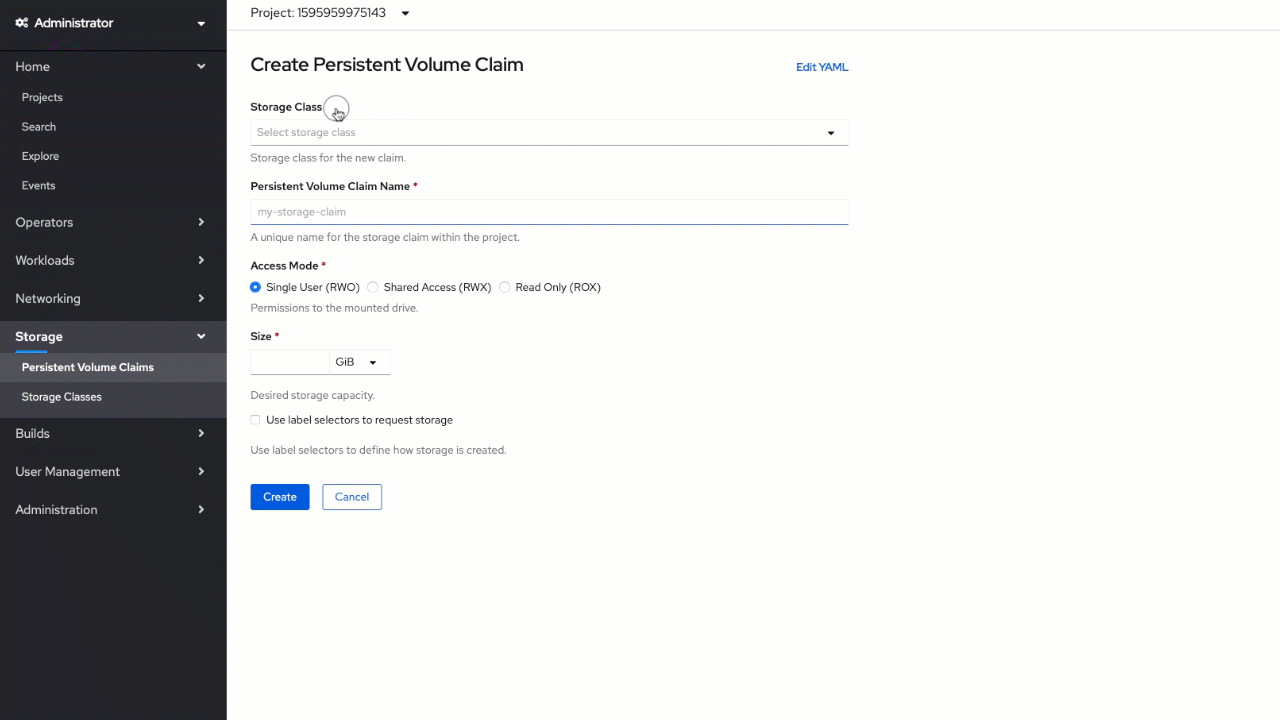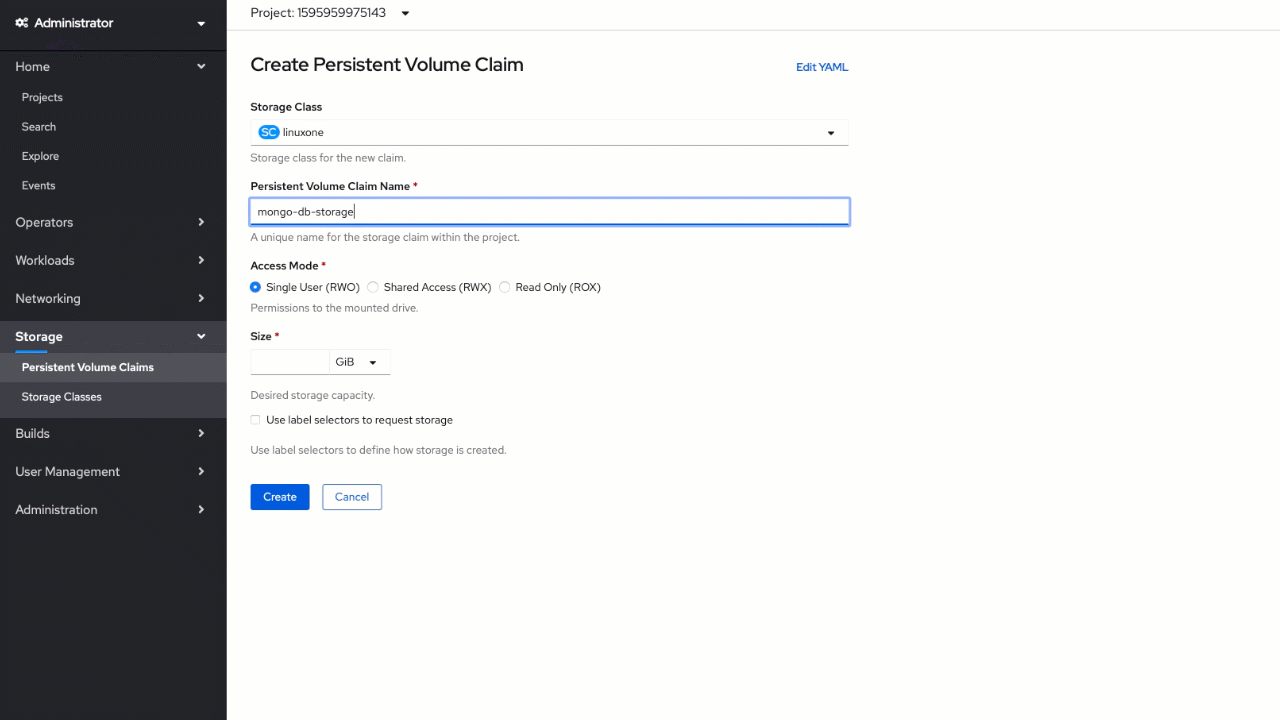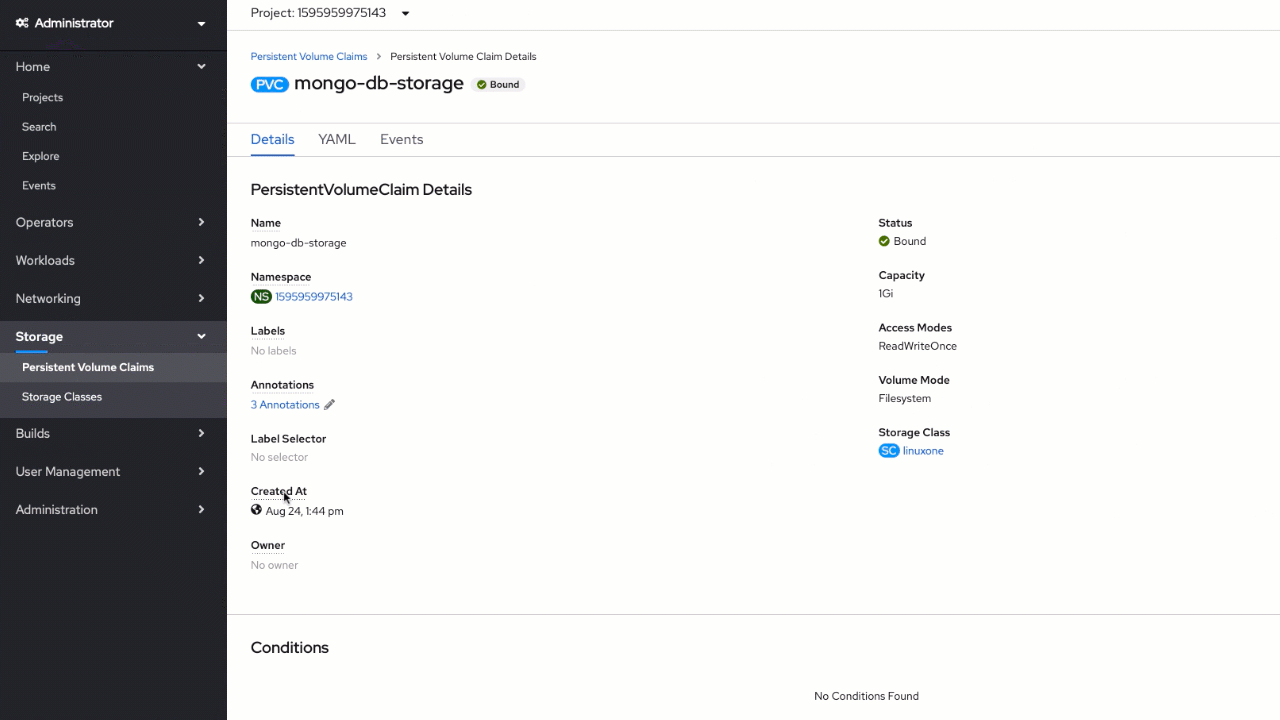
Inside the OpenShift web console, switch to the "Administrator" view and click on "Persistent Volume Claims" under the "Storage" section on the menu. Create a new volume claim using pre-defined "linuxone" as a "Storage class",
mongo-db-storage as the volume name, and set
1 GiB for "Size". Leave the "Single User (RWO)" setting selected.
Navigate to the "mongodb" deployment from "Workloads/Deployments" in the menu and scroll down to the volumes section.
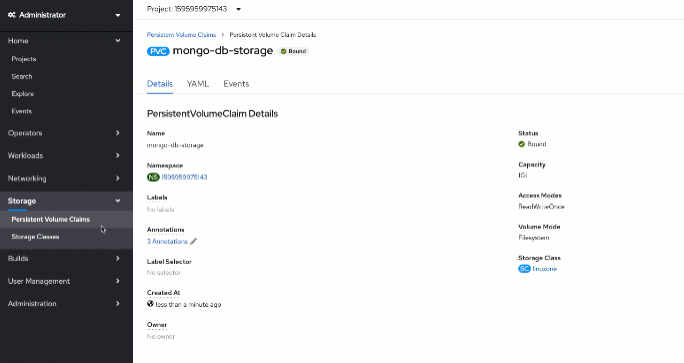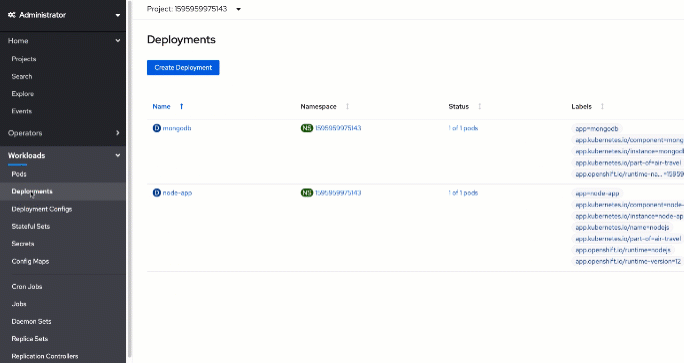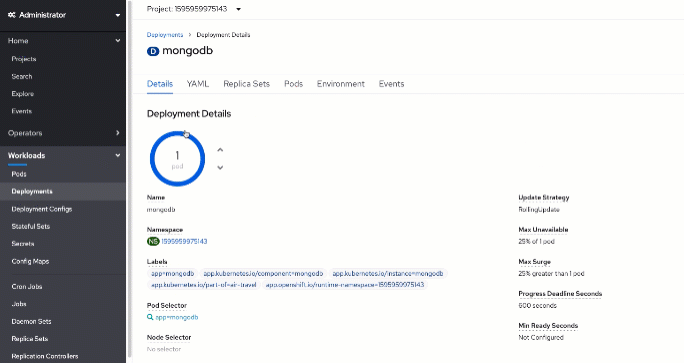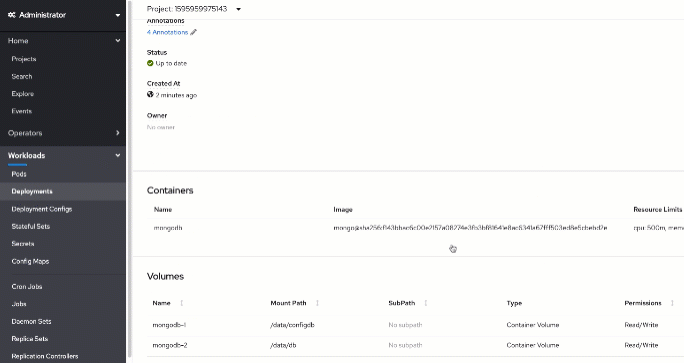
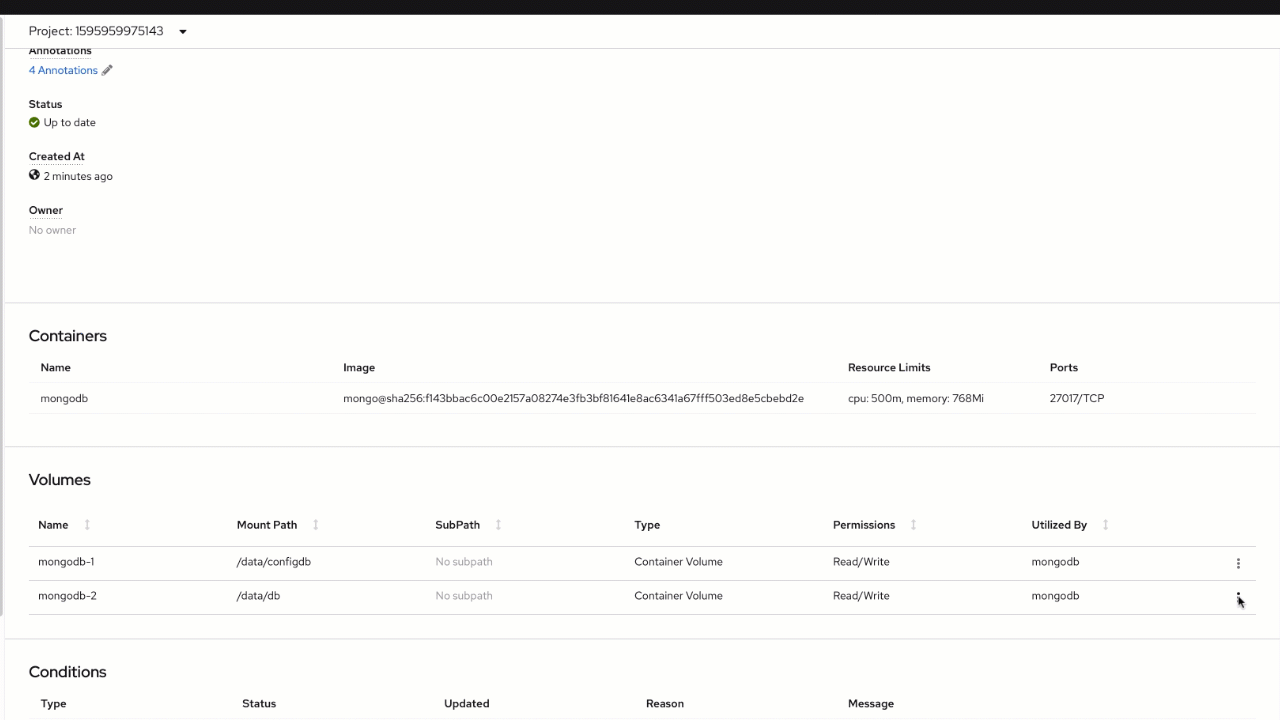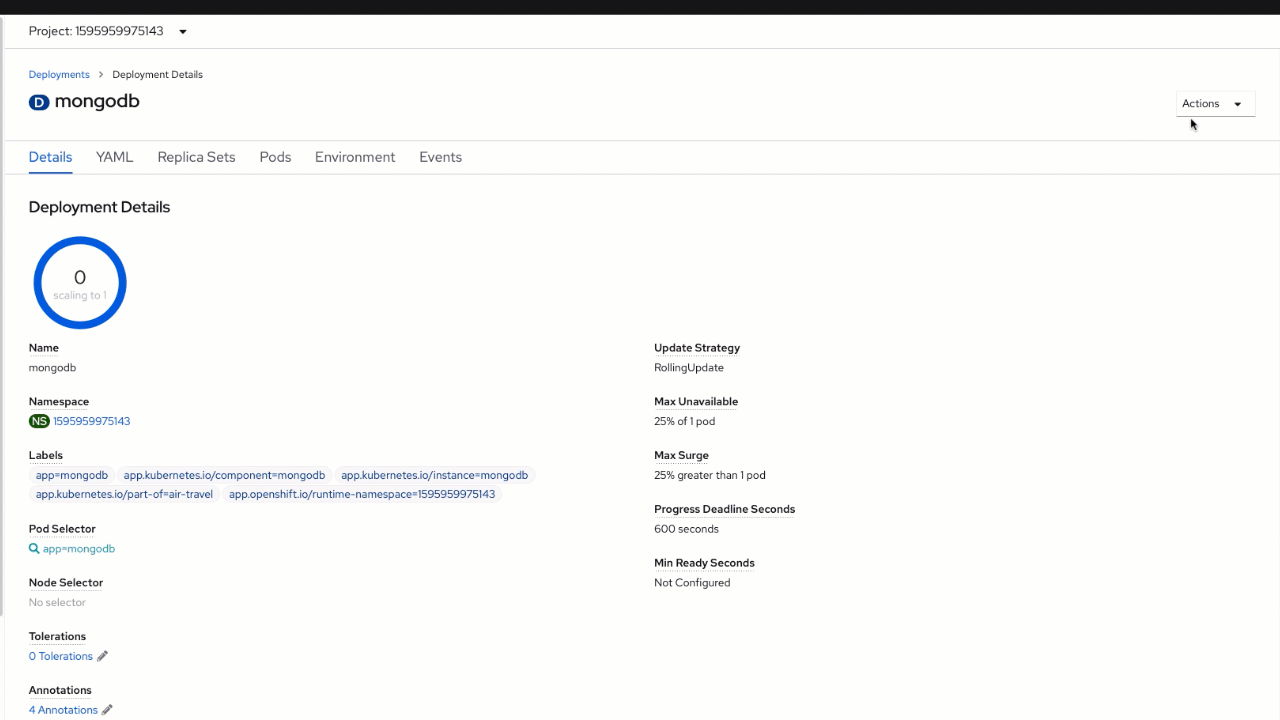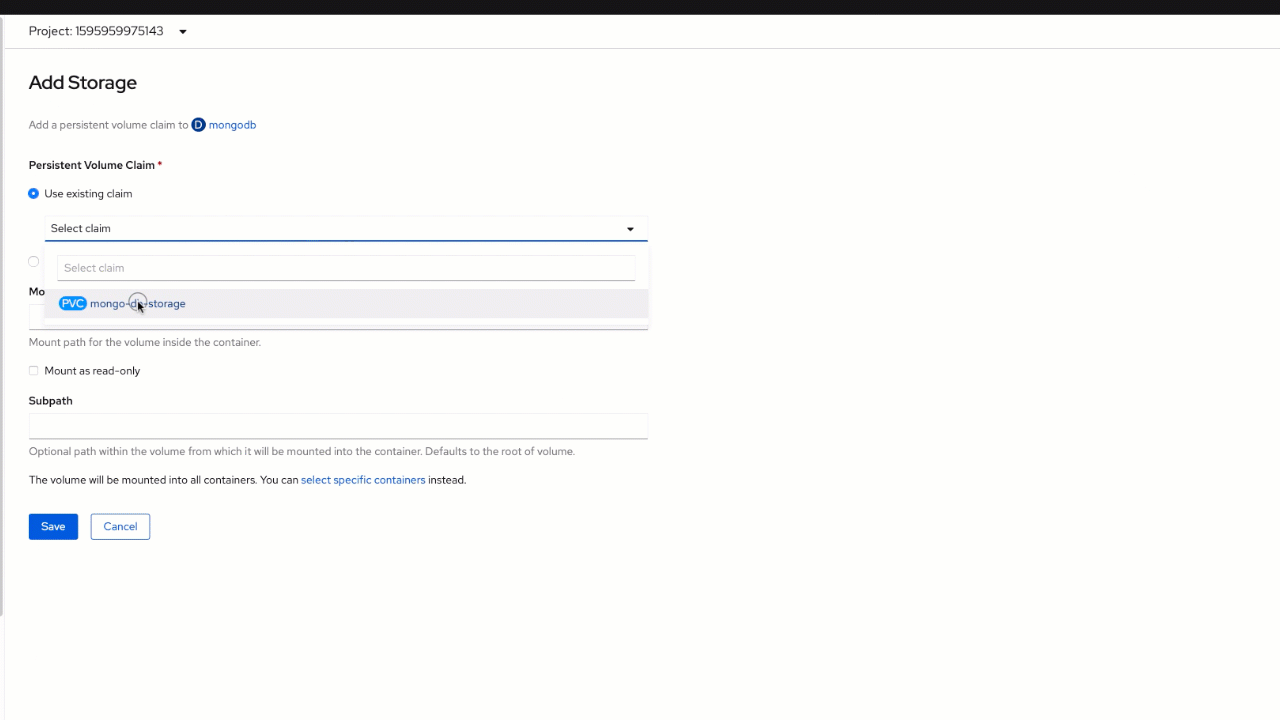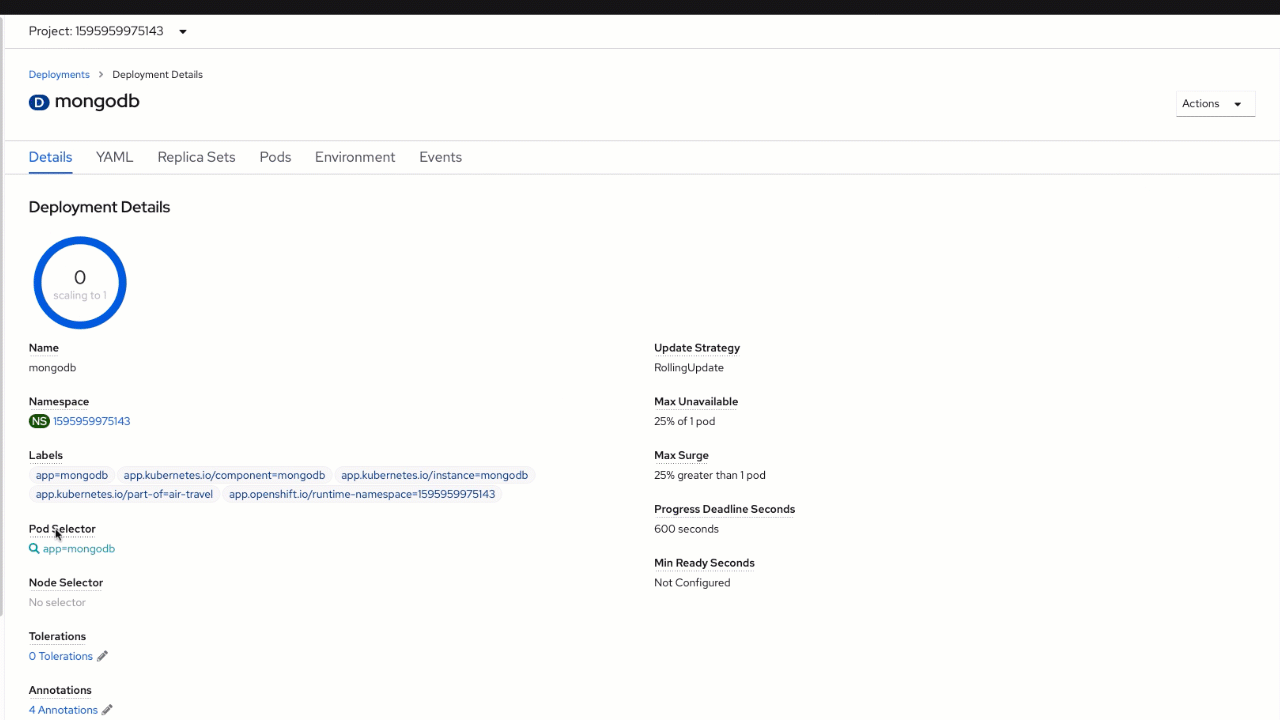
You will need to replace /data/db mount here. First, delete the existing "mongodb-2" volume by clicking the actions button on the right and selecting "Remove Volume". Then, use the global "Actions" menu in the top right corner of the page and click on "Add storage". You will need to select your existing claim and provide
/data/db as a "Mount Path" before saving.
Using the same "Actions" menu and "Edit Count" option scale to 0 and back to 1. Now, open the "AirTravel" application browser tab, try to perform few searches, and check that the "Database connection" window shows them as logged.
Scale back to 0 and then 1 again, and, finally, verify that your logged data still exists using the "AirTravel" application.
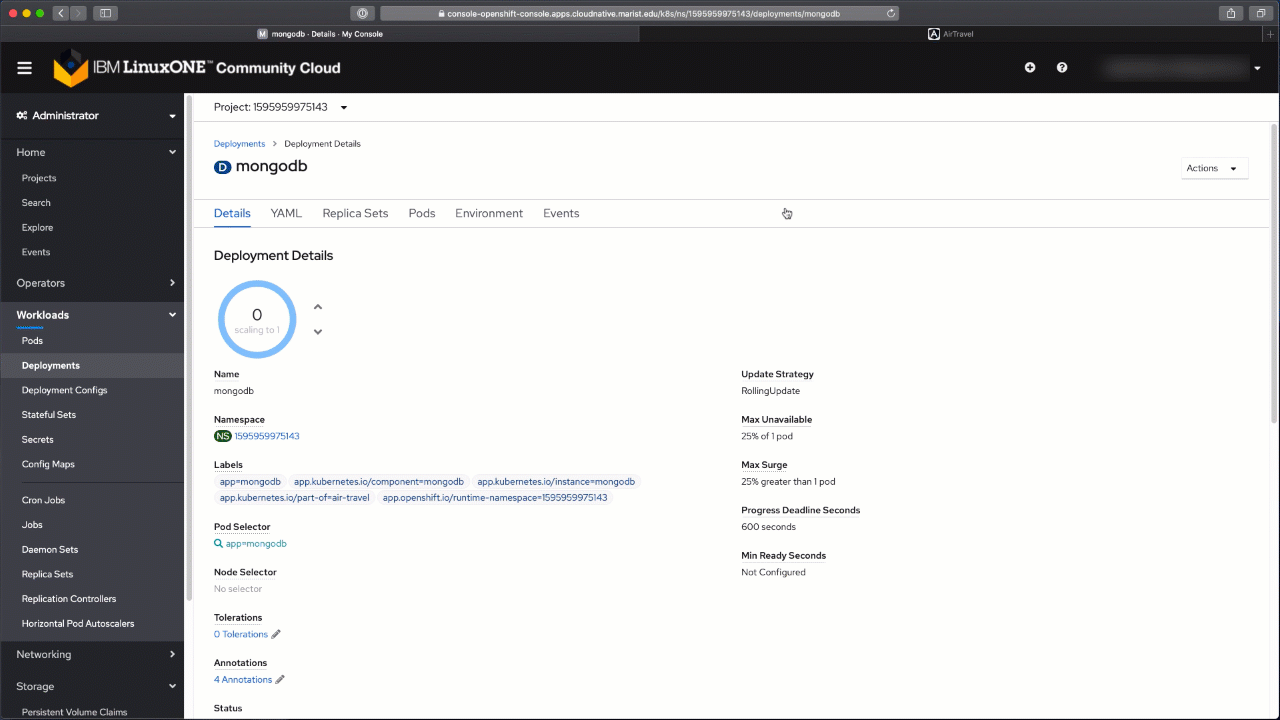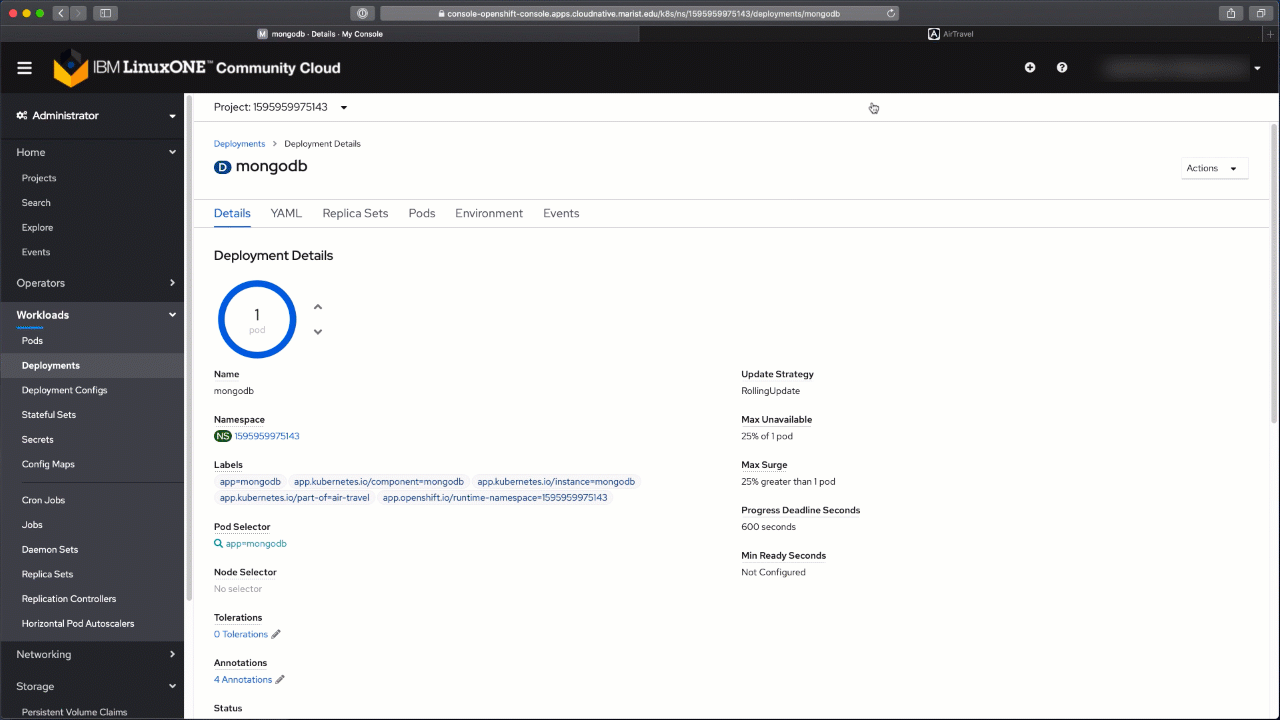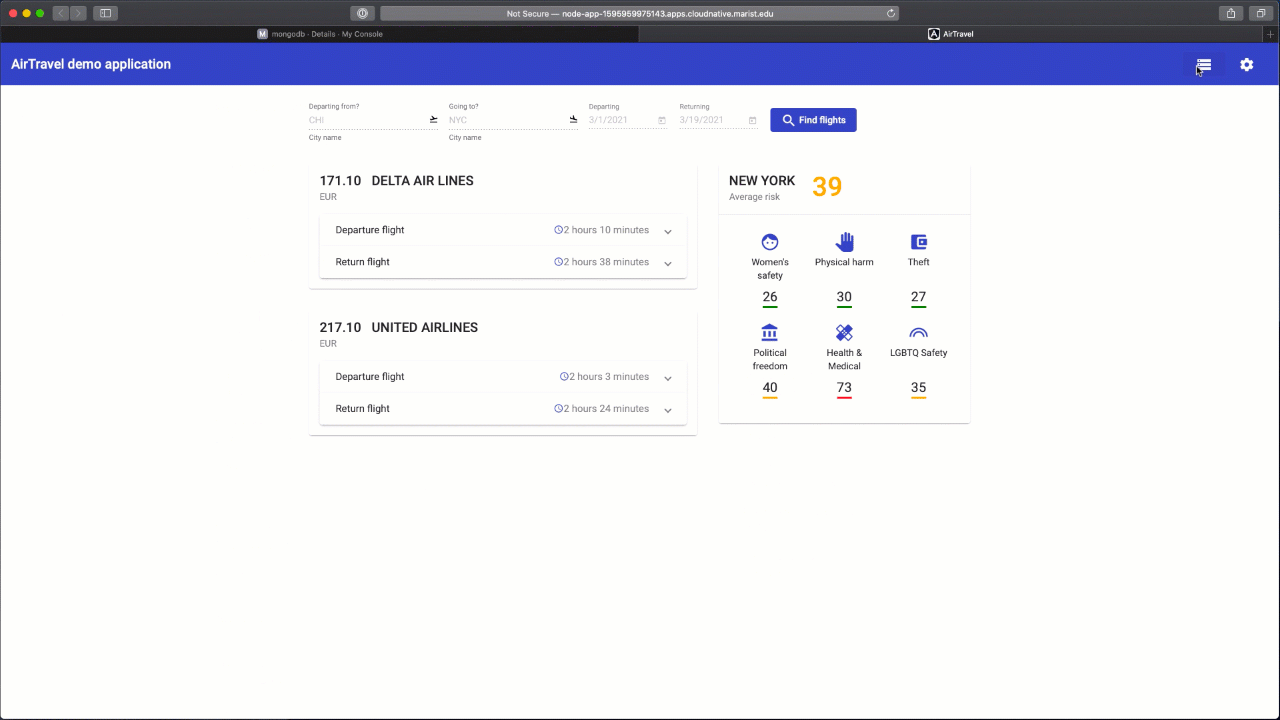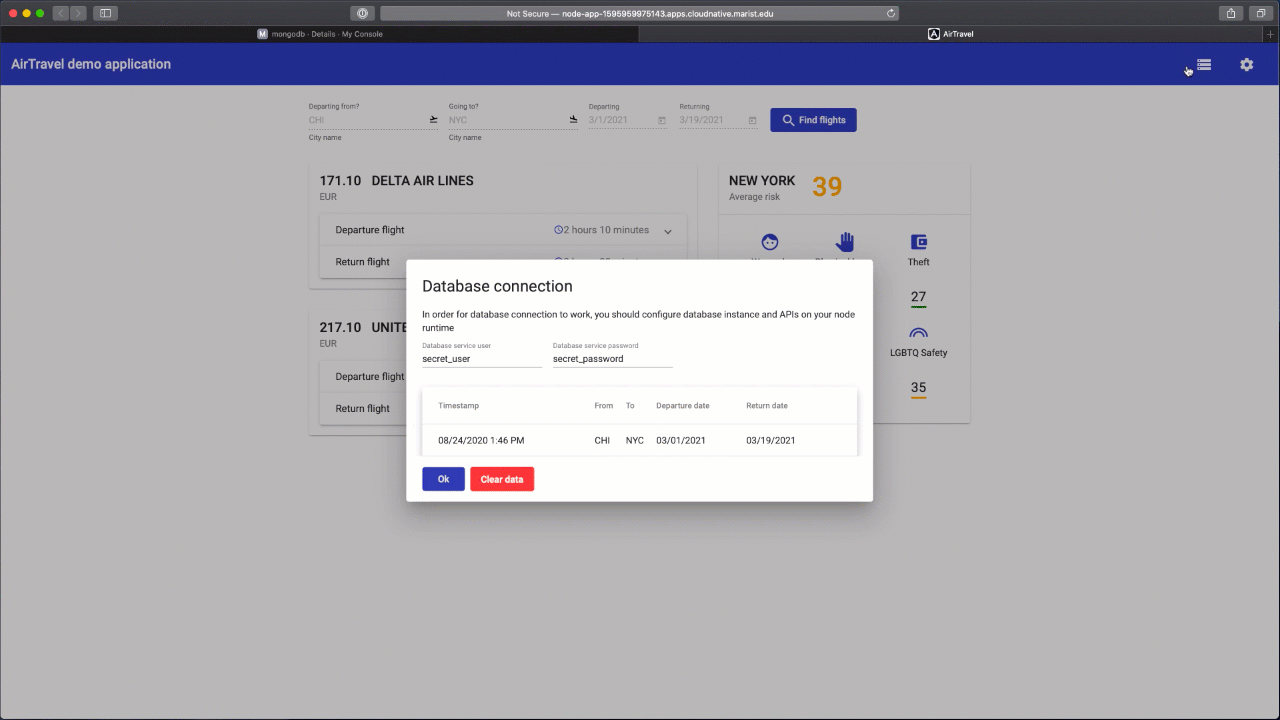
Bravo! You've made it to the end. I hope you've enjoyed the experience and learned new things! Check out our other
guides and tutorials.