Often, we come across business processes that involve PDF documents, and during automation development, some people find it difficult to map these documents. For this reason, I’ve gathered 3 types of PDF files that can be mapped with IBM RPA using different techniques for each of them and I’ll show you all of that in this article.
.
PDF documents are standardized by ISO 32000, the idea is to have an agnostic file format to present documents, regardless of Operating System and software used, encapsulating all sorts of resources (fonts, images, graphs, links, forms and programming logic) in one single file type.
One point of attention is related to the accuracy of data, which is related to the PDF type. Here’s the 3 types of PDF and how to map each one of them:
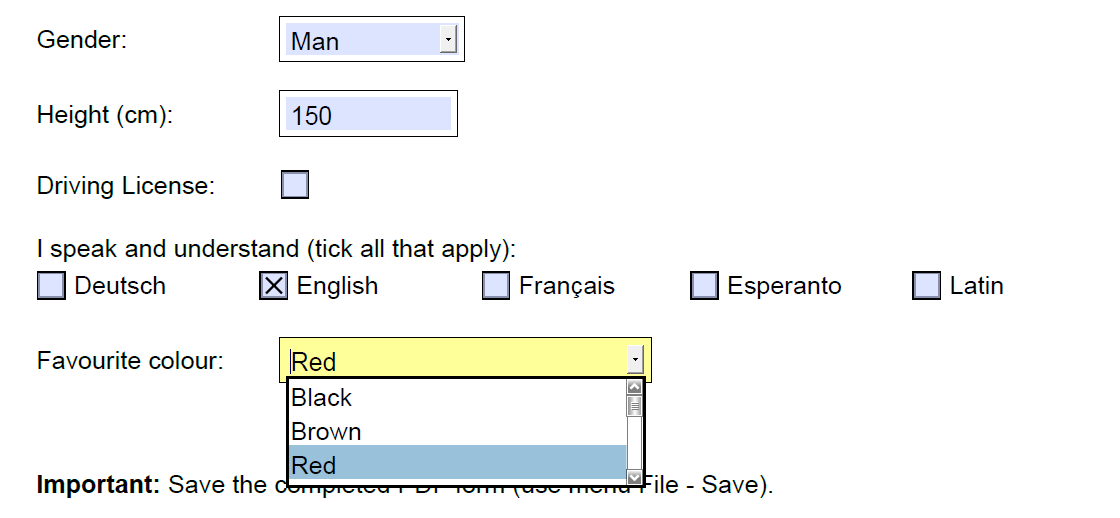
- Form PDF:
- Similar to a web form, this type of file contains input Fields to be filled out, as well as other kinds of selection fields.
- To map this type of PDF, you can use the “Field Mapper” tool. This tool leverages the following commands to perform its actions:
- Get PDF Field(pdfGetValue): Gets the value of a specific field in an editable PDF file.
- Assign Value to PDF (pdfSetValue): Assigns a value to a specific field in a editable PDF file
- Text PDF:
- Generally considered to be the “easiest” PDF type to map, as IBM RPA can access its structure and extract data straight from the file’s base, thus making the data accuracy for this type of PDF to be the highest among all 3 types.
- To map this type of PDF, we use the “Region Selector” tool, which generates the following commands when not OCR is not enabled:
- Get PDF Region Text (pdfRegionText): Gets the text of a region of the PDF file, according to the specified coordinates.
- Image PDF:
- This type of PDF file is comprised by an image, which makes it impossible to get data from the file’s structure itself, so in this case, we need to use OCR (Optical Character Recognition) to extract the text from the image. In this type of file, the accuracy of the data obtained is affected by various factors, which diminishes the level of confidence in the data.
- In this case, we have the possibility of using two different tools to extract data, according to the PDF format.
- Fixed fields, i.e. static document models that are always structured the same, can be mapped by using the “Region Selector“ tool with OCR, by enabling the OCR switch within the tool itself.
- Dynamic Fields, i.e. documents that may vary their structure, can be mapped with “Extract PDF Text”. This command uses a given word as an anchor to get the text in relation to said word. (extractPdfText command)

OCR (Optical Character Recognition) is a technology that recognizes characters in an image. Combining OCR with Artificial Intelligence makes several advanced features possible, e.g., recognizing car license plates in a Picture, where an AI algorithm is trained to identify the vehicle, then its license plate, from which OC can obtain the characters from.
Depending on the quality of the PDF file, when applying OCR we can have very low accuracy, for that I wrote another blog (
How to Improve OCR Accuracy) where I explain how we can have greater accuracy when we use OCR, give it a read.
I hope this has been insightful. Until next time!