前回の blog で ”AI がシステムが止まる前に教えてくれる”という話を書きました。
AIOpsのことを紹介する前に、過去から現在も行われている一般的な監視についておさらいしたいと思います。
それは、監視製品から CPU・メモリ・ハードディスクなどの情報を取得して、問題が起こりそうな閾値を超えたらメールやパトライトで通知するという方法です。
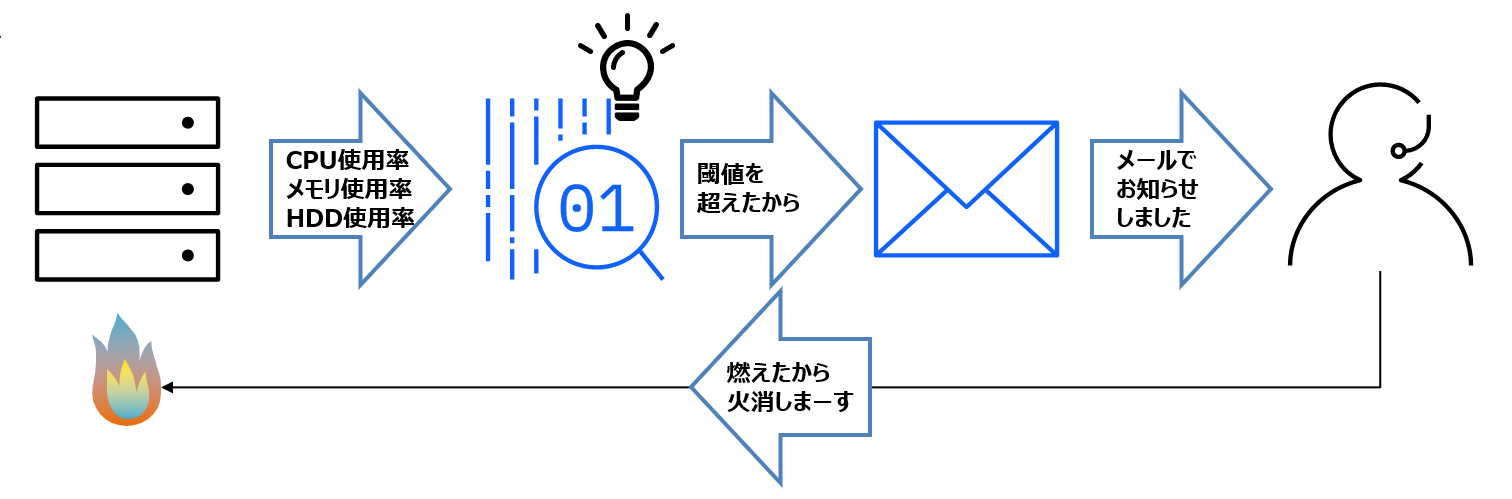
閾値を低く設定すれば、システムが止まる前に問題は解決できるかもしれません。ただ、閾値は低すぎても余計なアラートメールが増えるだけになってしまって、アラートメールに対する感度が落ちてしまい、人が原因できちんと対応できなくなるケースもあります。逆に閾値が高すぎても、運用者が問題に反応できなくなるのです。
このように、閾値をどのくらいに設定すべきなのかというのも悩みの一つの種です。システムごとに適切な閾値を設定して、問題が起こったときに見直すような運用の場合、システム全般に熟知をしたメンバーがいないと、値を決めきれなかったり値が適切なものではなくなったりします。
一か月に一回リブートすればいいかとか、目の前にサーバーがあるから落ちたら再起動すればいいやと割り切るのも一つの方法ですが、世の中には1分落ちたら何万ドルも損をするようなシステムもあるわけで、特にお客様にサービスを提供するようなシステムでは、そんな悠長なことでは済まされないのが現実です。
参考までに、情報処理推進機構がまとめていた【情報システムの障害状況一覧】を眺めてみると、背筋が凍るようなシステム障害が一覧となっています、ご興味があれば世の中でどんな恐ろしいシステム障害が起こっているか確認してみるといいでしょう。(2019年でとりまとめは終了しています)
では、運用者からみて突発的に発生する障害をどのように防いでいくべきか。もちろん一つの方法ですべてが防げるわけではありませんが、AIOPSという観点から対応できる方法をこの後のblogで紹介していこうと思います。